Zheng Liu,Xiaolan Zu,Xingyu Luo,Zihang Wang,Jierui zhang,Yehui wang, Liang Wang, Xianping Tao Department of Computer Science and Technology, State Key Laboratory for Novel Software Technology, Nanjing University Huawei Technologies Co, Ltd. OSS Compass
Abstract
This study proposes a method to predict the future activeness of open source projects using OSS Compass indicators. It employs a feature-based time series classification approach, extracting statistical features from OSS Compass indicator series and using machine learning algorithms for prediction. The method demonstrated an accuracy of nearly 90% in cross-validation on a dataset of around 600 projects and about 80% accuracy on a larger set of over 10,000 repositories, indicating its practical applicability. The results partially reflect the future health status of open source projects, demonstrating the effectiveness of the OSS Compass indicator system in measuring the health of open source software. The method could provide valuable insights for users, developers, investors, and managers of open source software.
1 OSS Compass Open Source Project Health Metrics Dataset
1.1 Data Preparation
This research encompasses two principal datasets, designed to provide comprehensive information to support our study. Initially, we have the expansive dataset A, which includes data from 20,213 repositories. This dataset's vast scope encompasses a broad spectrum of open-source projects, offering a rich pool of reference materials for our analysis. Furthermore, we have curated a more focused subset, dataset B. This subset, extracted from the larger dataset A, was selected based on key metrics such as star and fork counts of open-source projects, thereby representing the most influential and exemplary projects within the open-source community. Dataset B comprises 735 repositories, whose data are pivotal for extracting features relevant to our research. We then gathered metrics time-series data for each repository, categorized into four dimensions and comprising 80 metrics (including a time dimension), with each metric forming a time series directly corresponding to each repository (zero imputation was employed for missing data).
1.2 Data Cleaning
Upon an intensive review of the collected metric data, we engaged in a rigorous data filtering process to ensure the integrity and reliability of the datasets. Initially, repositories with challenging data retrieval, either due to data scarcity or the presence of irregular, 'dirty' data, were excluded. This filtration resulted in a refined dataset A, now consisting of 20,181 repositories, replete with all requisite metric information. Similarly, dataset B was condensed to 600 repositories, all demonstrating exemplary data quality and usability, laying a solid foundation for further analysis.
1.3 Open Source Repository Selection
Considering the specific requirements for time series length in our predictive tasks, we implemented several data selection and processing steps to ensure the quality and appropriateness of our datasets. Repositories with insufficient time series length, including empty repositories, were excluded as they could not provide adequate data for reliable predictions. Additionally, our focus was on utilizing time series leading up to a project's transition to inactivity; hence, repositories that remained inactive throughout the recorded period were also discarded to ensure the feasibility and accuracy of model training and predictions.
After these meticulous selection and processing steps, we finalized dataset A, comprising 19,413 repositories, and dataset B, consisting of 585 repositories, both tailored to meet the requirements of our predictive tasks. Subsequent analyses were conducted to determine the activity status of these repositories, with specific criteria outlined in section 1.4. In dataset A, 5,411 repositories were deemed active and 14,002 inactive, reflecting an uneven distribution of labels, which aligns with the real-world scenario of fewer active projects. In contrast, dataset B exhibited a more balanced label distribution, with 325 active and 260 inactive repositories, beneficial for subsequent predictive tasks as it enables the model to more effectively learn and predict performance across different repository states.
1.4 Criteria for Determining Active/Inactive Status
The aforementioned criteria serve as independent variables in our predictive analysis. To establish the dependent variable, each repository sample was analyzed and labeled as inactive or active, facilitating the training and prediction process. A repository was classified as inactive if it met either of the following conditions:
1.A lack of activity, defined as commits, branch creations, issue tracking, or pull requests, over a period exceeding one year
2.Minimal commit activity within the past year, indicating sporadic engagement insufficient to maintain active status.
Based on these definitions, each repository was analyzed and accordingly labeled, ensuring an objective, quantifiable basis for subsequent analysis and predictions.
2 Feature-Based Method for Predicting Project Activeness
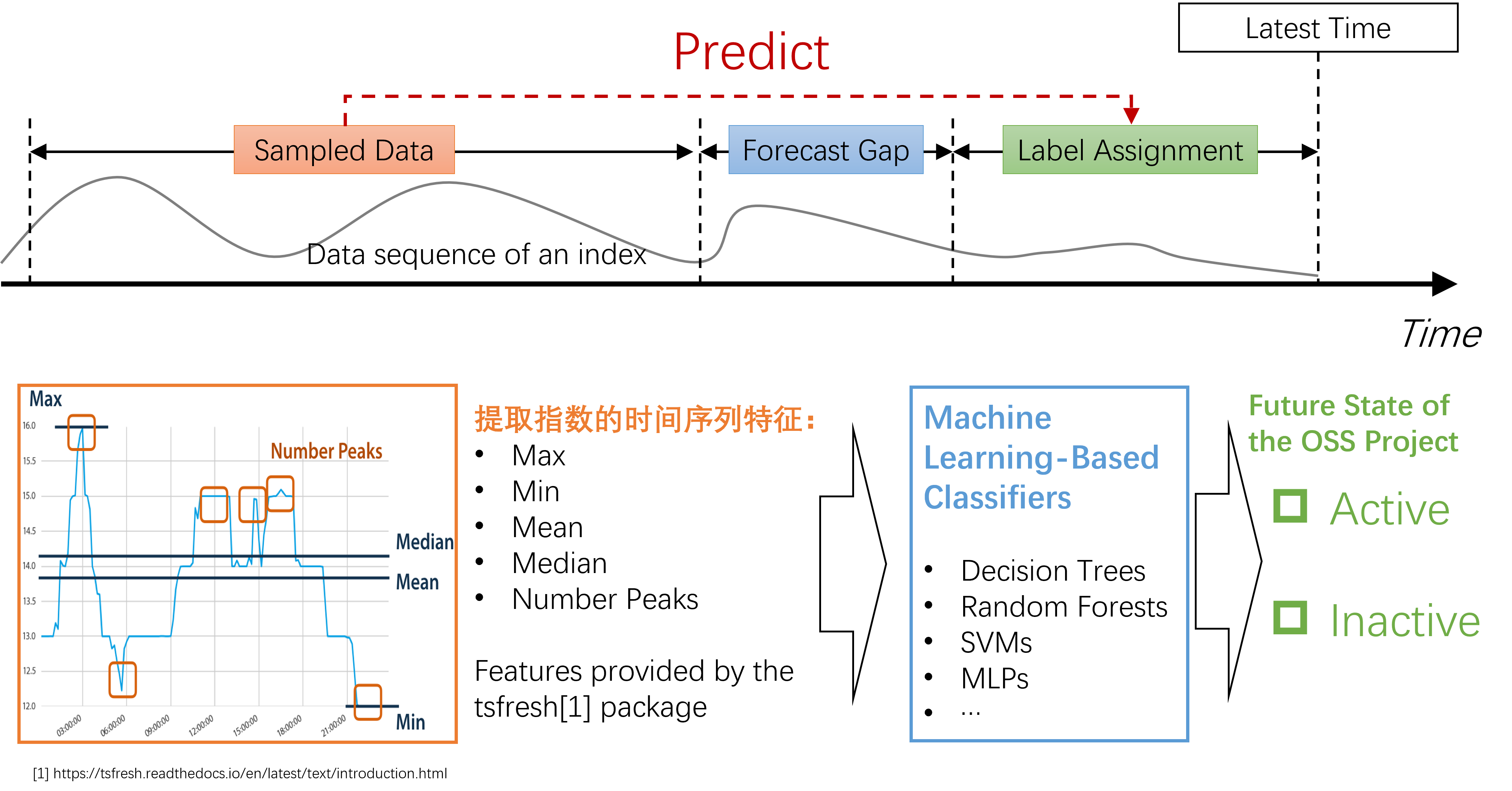
Figure2-1 Predictive Method Based on Feature Extraction and Classical Machine Learning Techniques
As illustrated in Figure 2-1, the feature-based approach is a classic machine learning methodology typically employed for processing time series data. The crux of this approach is to transform time series data into a set of features, which include, but are not limited to, statistical metrics like mean, median, maximum, minimum, and variance. By extracting these features, we convert the original time series data into a non-time series CSV data table, enabling the application of traditional data analysis and machine learning techniques such as KNN and Decision Trees. The advantage of this method lies in its ability to simplify complex time series data into fixed-dimension feature vectors, facilitating subsequent data processing and modeling. Additionally, feature extraction helps reduce noise and redundancy in the data, enhancing model stability and performance. The typical steps in the feature-based approach include:
Data Collection: Initially, time series data is collected, which may originate from sensors, financial markets, meteorological stations, or other domains.
Feature Extraction: This involves the computation of various statistical metrics such as mean, median, standard deviation, kurtosis, skewness, and the application of signal processing techniques like Fourier and wavelet transforms for frequency domain feature extraction.
Data Transformation: The extracted features are compiled into a tabular dataset, typically saved as a CSV file, with each row representing a time series sample and each column a feature.
Data Preprocessing: This step includes handling missing values, standardization, normalization, etc., to ensure data stability and usability in modeling.
Modeling and Analysis: Traditional machine learning algorithms such as Linear Regression, Decision Trees, Random Forests, Support Vector Machines, etc., are employed for modeling and analysis of the feature-based data.
Model Evaluation: The model's performance is assessed using techniques like cross-validation and metrics such as accuracy, mean squared error, ROC curve, etc.
Key steps in this process include feature extraction and the design of learning algorithms, elaborated as follows.
2.1 Extracted Feature Set
In this work, we extracted features from 72 indices across four dimensions:
Activity Score: 19 indicators related to activity, such as active_C2_contributor_count_activity, active_C1_pr_create_contributor_activity, etc. (refer to Appendix B.1).
Code Quality Guarantee: 25 indicators including contributor_count_codequality, contributor_count_bot_codequality, etc. (see Appendix B.2).
Community Service and Support: 15 indicators such as issue_first_reponse_avg_community, issue_first_reponse_mid_community, etc. (refer to Appendix B.3).
Group Activity: 13 indicators like contributor_count_group_activity, contributor_count_bot_group_activity, etc. (see Appendix B.4).
Additionally, basic project information such as the project name and grimoire_creation_date were included in the feature computation. However, since these do not fall under the indicators and models proposed by OSS Compass, they were not subjected to feature extraction. For the numerical features in the 72 indices, multiple statistical functions were selected, including length, large standard deviation, mean, maximum, minimum, variance, etc., resulting in 16 representative statistical quantities (detailed in Appendix C). These were used to compute corresponding feature vectors. Further, based on the preferences of different classifiers, two sets of typical feature collections were selected through feature selection:
Feature Set 1: Comprising 596 distinct features for classifiers like XGBoost, RandomForest, AdaBoost, etc.
Feature Set 2: Including 134 features for classifiers such as KNN, Logistic, SVM, etc.
Details of these two feature sets can be found in Appendix B.
2.2 Classification and Predictive Algorithms
XGBoost (Extreme Gradient Boosting): XGBoost enhances model performance by combining multiple decision trees, offering remarkable accuracy and robustness. It iteratively refines the model by optimizing the loss function, preventing overfitting, and supports feature selection. Widely employed in data science challenges like Kaggle competitions, XGBoost stands out for its efficiency in handling complex datasets.
RandomForest: As an ensemble learning method based on multiple decision trees, RandomForest classifies or regresses based on collective tree voting. It introduces randomness to mitigate overfitting risks, boasting excellent generalization capabilities and automatic feature selection. Suitable for a variety of data types, RandomForest is user-friendly and demands minimal hyperparameter tuning.
AdaBoost (Adaptive Boosting): An iterative learning algorithm, AdaBoost enhances model performance by integrating multiple weak learners. It adjusts sample weights based on previous learning errors, focusing more on incorrectly classified samples. Commonly used for binary classification problems, AdaBoost in this project employs decision trees as base learners, denoted as AdaBoost + DecisionTree.
Logistic Regression: A widely used linear model for classification problems, Logistic Regression employs a logistic function to estimate the relationship between input features and a binary target. Known for its simplicity and interpretability, it's frequently applied in probability-based predictions like customer churn or disease diagnosis.
SVM (Support Vector Machine): SVM is a powerful algorithm for classification and regression. It maximizes the margin between different categories by finding the optimal hyperplane. Excellently performing in high-dimensional spaces, SVM can adapt to various data types with different kernel functions.
KNN (K-Nearest Neighbors): KNN, an instance-based learning algorithm, is used for classification and regression. It makes predictions by measuring the nearest K neighbors to a query point. While KNN is straightforward and easy to comprehend, it may be less efficient for large datasets.
Built upon a multitude of classical machine learning algorithms, feature-based classification prediction methods offer diversity, simplicity in implementation, and a wealth of tools. Moreover, by extracting features with clear physical significance to characterize projects, these methods provide high interpretability.
3 Empirical Study Design and Results
This section, grounded on the aforementioned methods, conducts empirical research to validate the effectiveness of the OSS Compass indicator system in predicting future activity and health of projects, supported by machine learning and AI methodologies.
3.1 Methodology of Empirical Study
This subsection introduces the datasets, methods, and evaluation metrics used in the empirical research.
3.1.1 Dataset
Two datasets, A and B as introduced above, were utilized. We initially trained and predicted on dataset B, observing commendable performance. Then, we applied the model to dataset A to assess its generalization capability, i.e., how the model performs in unseen real-world contexts.
3.1.2 Validation Method
Ten-Fold Cross-Validation: Employing ten-fold cross-validation ensured robustness and generalizability in evaluating our classification models. The dataset was divided into ten subsets, with nine serving as training sets and one as a test set, in a repeated process to mitigate the impact of randomness on performance assessment. This method reliably gauges model performance across different data subsets, averting overfitting.
Feature Selection Experiment: Utilizing Tsfresh's select_features function and adjusting the fdr_level parameter, we obtained a carefully curated feature set. These features significantly contributed to classification tasks, enhancing model performance. Our selection, based on statistical significance, managed FDR (False Discovery Rate) stringency. A lower fdr_level ensured highly significant features were chosen, aiding in developing high-performance, reliable classification models.
3.1.3 Evaluation Metrics
The following metrics are commonly used to evaluate the performance of classification models and to verify their effectiveness in processing data:
- Accuracy:
Accuracy is a fundamental metric for assessing the performance of a classification model.
It represents the ratio of the number of correctly classified samples to the total number of samples.
Formula: Accuracy= (TP+TN) / (TP+TN+FP+FN)
TP:True Positive (Number of samples correctly predicted as positive)
TN:True Negative (Number of samples correctly predicted as negative)
FP:False Positive (Number of samples incorrectly predicted as positive)
FN:False Negative (Number of samples incorrectly predicted as negative)
- Precision:
- Precision measures the proportion of samples that are actually positive among those predicted as positive.
- ormula: Precision = TP/(TP+FP)
- Recall::
Recall measures the proportion of positive samples correctly identified by the model out of the total positive samples.
Formula: Recall = TP/(TP+FN)
- F1 Score:
- The F1 Score is the harmonic mean of precision and recall, used for a comprehensive assessment of model performance.
- Formula: F1 Score = 2PR/(P+R)
- AUC(Area Under the Curve):
- AUC is the area under the ROC (Receiver Operating Characteristic) curve, used to measure the performance of a model at different thresholds.
- The ROC curve plots FPR (False Positive Rate) on the x-axis against TPR (True Positive Rate, or Recall) on the y-axis, illustrating classification performance at various thresholds.
- An AUC value closer to 1 indicates better model performance.
- Confusion Matrix:
- The Confusion Matrix is a matrix that displays the classification results of a model.
- It includes the counts of True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN).
- It is usually presented in a tabular form for a clear, visual representation of model performance.
3.2 Assessment Results: Validation Results on Dataset B
Utilizing ten-fold cross-validation, we employed classifiers including XGBoost, RandomForest, AdaBoost, SVM, KNN, Logistic Regression, and their ensemble models for prediction. The results were measured comprehensively using various metrics as described earlier. XGBoost, RandomForest, and AdaBoost demonstrated effective performance, with accuracies nearing 90%. For the Logistic Regression method, performance was weaker in Feature Set 1 due to a high number of features leading to predictions tending towards all-ones, likely due to overfitting. However, in Feature Set 2, its accuracy reached 86%. SVM and KNN showed moderate performance, sensitive to data and requiring parameter tuning and specific data-condition optimization. Ultimately, we selected XGBoost, RandomForest, and AdaBoost for multiple prediction integrations, achieving an overall prediction accuracy of 90%. Combining multiple models' predictions can enhance overall performance, reduce the risk of overfitting, and decrease the number of prediction errors by a single classifier. The performance of each classifier is detailed below:
3.2.1 Classification Prediction Performance Assessment Based on Feature Set 1
As described in section 2.1, Feature Set 1 includes 596 different features used for classifiers such as XGBoost, RandomForest, and AdaBoost.
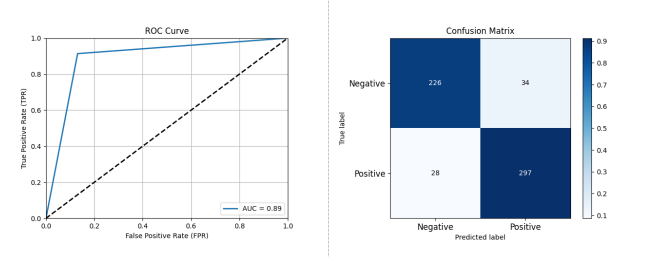
Figure 3-1: Performance Assessment of Open Source Project Activity Classification Prediction Based on XGBoost
As shown in Figure 3-1, using XGBoost on a dataset of 585 open source projects with ten-fold cross-validation, the performance was: Accuracy: 0.8940, Precision: 0.8973, Recall: 0.9138, F1 Score: 0.9055, AUC: 0.8915. The confusion matrix reveals that XGBoost can accurately predict the future activity of projects based on OSS Compass indices.

Figure 3-2: Performance Assessment of Open Source Project Activity Classification Prediction Based on Random Forest
Figure 3-2 shows that using Random Forest, we achieved classification prediction performance close to that of XGBoost. With ten-fold cross-validation, the performance was: Accuracy: 0.8923, Precision: 0.9068, Recall: 0.8985, F1 Score: 0.9026, AUC: 0.8915.
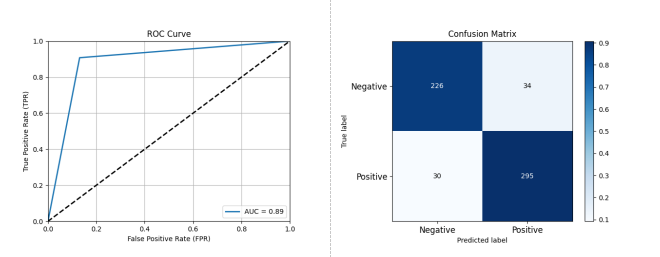
Figure 3-3: Performance Assessment of Open Source Project Activity Classification Prediction Based on AdaBoost + DecisionTree
As depicted in Figure 3-3, the AdaBoost + DecisionTree classifier also demonstrated strong predictive capability: Accuracy: 0.8906, Precision: 0.8967, Recall: 0.9077, F1 Score: 0.9021, AUC: 0.8885.
The performances of XGBoost, Random Forest, and AdaBoost were consistent, all achieving close to 90% classification accuracy. Minor differences in classifier performance, as shown, might result from randomness in the ten-fold cross-validation process.
3.2.2 Classification Prediction Performance Assessment Based on Feature Set 2
As mentioned in section 2.1, Feature Set 2 comprises 134 features, used for classifiers including KNN, Logistic Regression, and SVM. Compared to Feature Set 1, these classifiers achieved better results with Feature Set 2.
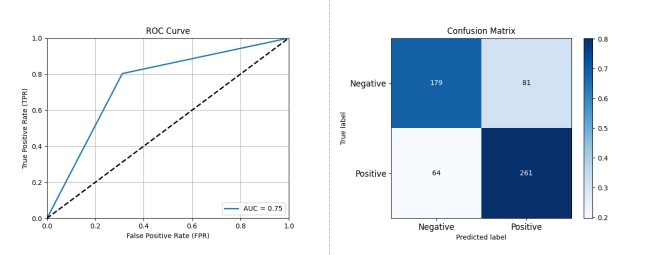
Figure 3-4: Performance Assessment of Open Source Project Activity Classification Prediction Based on KNN
As shown in Figure 3-4, the KNN method effectively predicted future activity levels of open source projects: Accuracy: 0.7521, Precision: 0.7632, Recall: 0.8031, F1 Score: 0.7826, AUC: 0.7457.
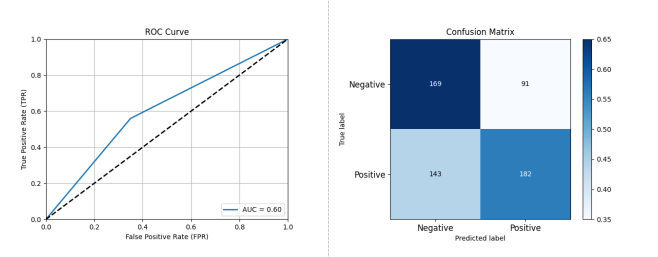
Figure 3-5: Performance Assessment of Open Source Project Activity Classification Prediction Based on SVM
As illustrated in Figure 3-5, SVM's classification prediction capability was relatively weak: Accuracy: 0.6291, Precision: 0.6812, Recall: 0.6246, F1 Score: 0.6517, AUC: 0.6296.
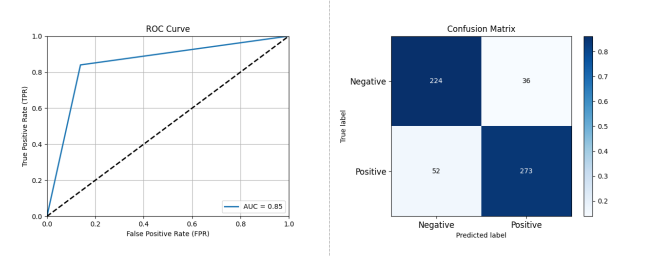
Figure 3-6: Performance Assessment of Open Source Project Activity Classification Prediction Based on Logistic Regression
As depicted in Figure 3-6, Logistic Regression showed superior performance to KNN and SVM in Feature Set 2: Accuracy: 0.8496, Precision: 0.8835, Recall: 0.84, F1 Score: 0.8611, AUC: 0.8508.
Compared to Feature Set 1, classifiers corresponding to Feature Set 2 were relatively weaker, but Logistic Regression approached the performance of Feature Set 1 classifiers.
3.2.3 Ensemble Learning and Overall Results
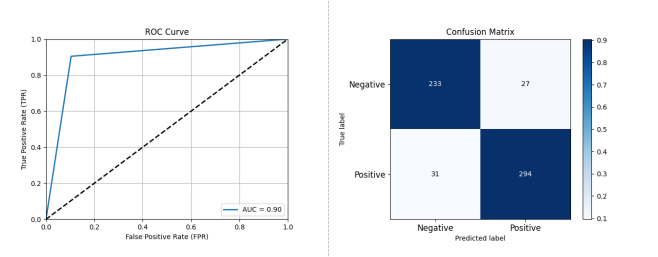
Figure 3-7: Performance Assessment After Ensemble of XGBoost, AdaBoost, and RandomForest Classifiers
Based on the aforementioned results, we opted for a majority-vote ensemble learning approach with the three classifiers from section 2.1 using Feature Set 1, achieving the best results: Accuracy: 0.9009, Precision: 0.9159, Recall: 0.9046, F1 Score: 0.9102, AUC: 0.9004.
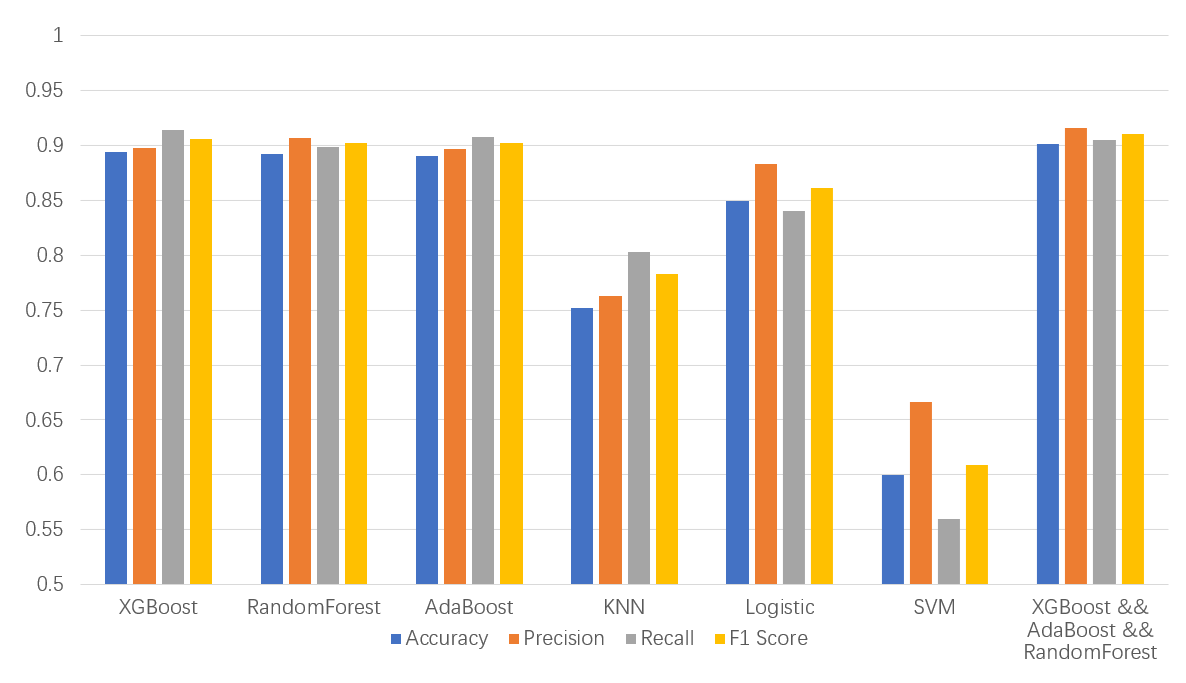
Figure 3-8: Overview of Prediction Results
Finally, Figure 3-8 summarizes the validation results on dataset B, listing the performance of different classifiers including accuracy, precision, recall, and F1 score. The results show that, except for KNN and SVM, the remaining classifiers achieved over 85% classification accuracy. The ensemble learning method combining multiple classifiers demonstrated the best classification prediction performance, showing promise for real-world application.
3.3 Assessment Results: Generalization Results on Dataset A
Utilizing the models trained on dataset B as described in section 3.2, which included XGBoost, RandomForest, AdaBoost, SVM, KNN, Logistic Regression, and their ensemble models, we tested these models on dataset A to evaluate their generalization capabilities. The performance of each classifier is detailed below:
3.3.1 Classification Prediction Performance Assessment Based on Feature Set 1
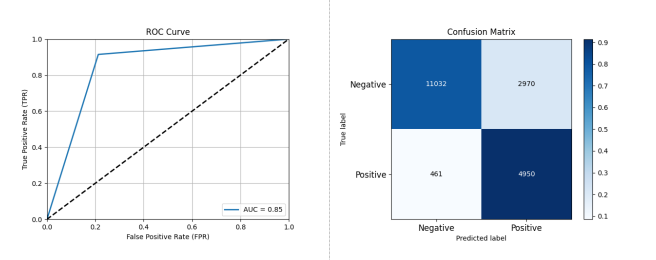
Figure 3-9: Performance Assessment of Open Source Project Activity Classification Prediction Based on XGBoost
As shown in Figure 3-9, using XGBoost on dataset A, the performance was: Accuracy: 0.8233, Precision: 0.6250, Recall: 0.9148, F1 Score: 0.7426, AUC: 0.8513.
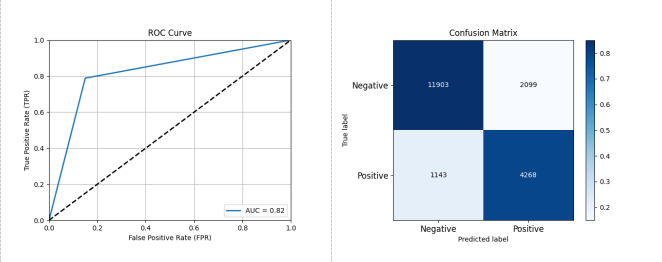
Figure 3-10: Performance Assessment of Open Source Project Activity Classification Prediction Based on RandomForest
As depicted in Figure 3-10, using RandomForest on dataset A, the performance was: Accuracy: 0.8330, Precision: 0.6703, Recall: 0.7888, F1 Score: 0.7247, AUC: 0.8194.
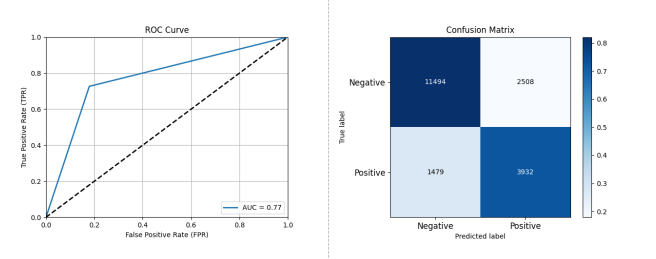
Figure 3-11: Performance Assessment of Open Source Project Activity Classification Prediction Based on AdaBoost
Figure 3-11 shows that using AdaBoost on dataset A, the performance was: Accuracy: 0.8940, Precision: 0.7946, Recall: 0.6106, F1 Score: 0.6636, AUC: 0.7738.
3.3.2 Classification Prediction Performance Assessment Based on Feature Set 2
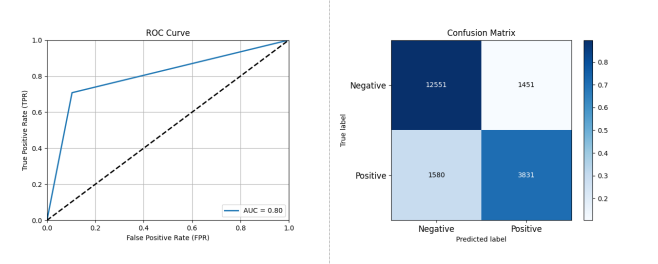
Figure 3-12: Performance Assessment of Open Source Project Activity Classification Prediction Based on KNN
As shown in Figure 3-12, using KNN on dataset A, the performance was: Accuracy: 0.8439, Precision: 0.7253, Recall: 0.7080, F1 Score: 0.7165, AUC: 0.8022.
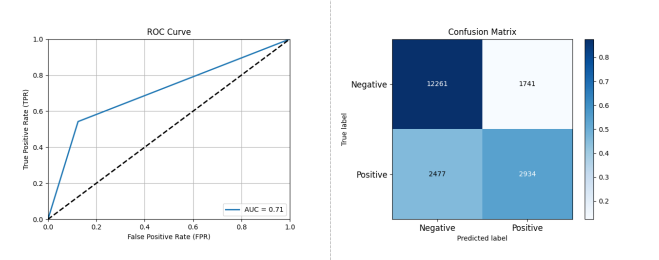
Figure 3-13: Performance Assessment of Open Source Project Activity Classification Prediction Based on SVM
Figure 3-13 reveals that using SVM on dataset A, the performance was: Accuracy: 0.7827, Precision: 0.6276, Recall: 0.5422, F1 Score: 0.5818, AUC: 0.7089.
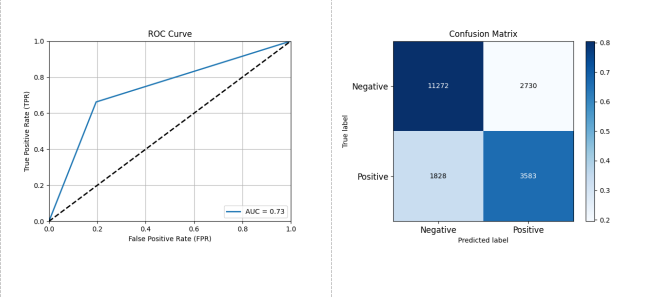
Figure 3-14: Performance Assessment of Open Source Project Activity Classification Prediction Based on Logistic Regression
As depicted in Figure 3-14, using Logistic Regression on dataset A, the performance was: Accuracy: 0.7652, Precision: 0.5676, Recall: 0.6622, F1 Score: 0.6112, AUC: 0.7336.
3.3.3 Ensemble Learning and Overall Results
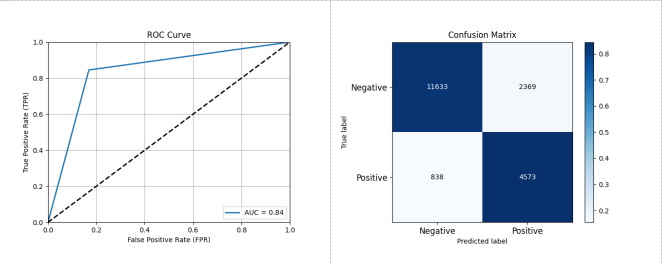
Figure 3-15: Performance Assessment After Ensemble of XGBoost, AdaBoost, and RandomForest Classifiers
As shown in Figure 3-15, using an ensemble of XGBoost, AdaBoost, and RandomForest on dataset A, the performance was: Accuracy: 0.8348, Precision: 0.6587, Recall: 0.8451, F1 Score: 0.7404, AUC: 0.8380.
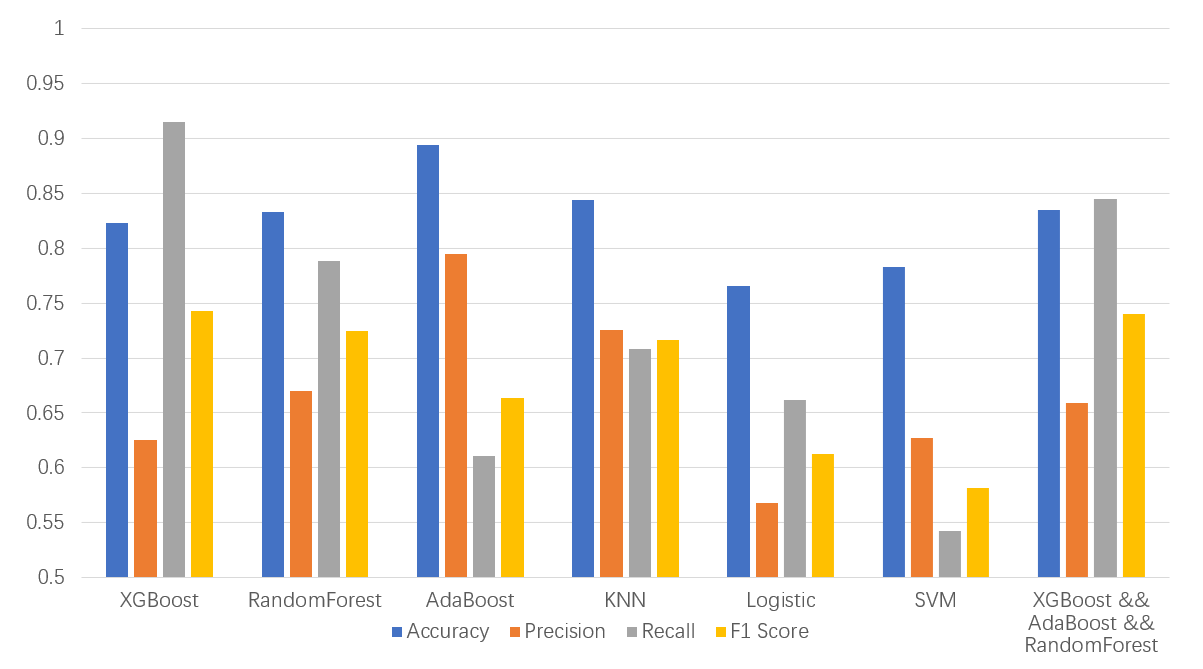
Figure 3-16: Overview of Prediction Results
Finally, Figure 3-16 summarizes the generalization results on dataset A, listing the performance of different classifiers including accuracy, precision, recall, and F1 score. The results indicate that KNN and the ensemble learning method combining multiple classifiers exhibit strong generalization capabilities and effective classification prediction. These two models are recommended for future predictions.
3.4 Threats to Validity
Firstly, concerning internal validity threats, although mature machine learning models were employed, the effectiveness of these models is not extensively validated due to the limited data volume of the dataset. Thus, their practical applicability remains to be further experimented and proven in real-world scenarios. On another note, this method was exclusively applied to the model indices of OSS-Compass. While theoretically suitable for all time series prediction scenarios, its applicability in other contexts requires further validation.
4 Recommended Deployment Scheme
Based on the experimental results, it is recommended to use KNN and an ensemble learning approach combining multiple classifiers as the learning models. After comprehensive training on the large-scale dataset A, these models should be deployed on practical platforms for actual use.
Acknowledgments
Gratitude is extended to the contributors of the open-source community and the OSS Compass platform for providing the data. Thanks are also due to the guiding teachers and fellow students. This work was supported by the Nanjing University Undergraduate Innovation Training Program "Research on Health Prediction Technology of Open Source Software Projects Based on Metric Indicators."
Appendix A: Feature Sets
A.1 Feature Set 1 (Comprising 596 features, named as: Index Name__Feature Function)
- commit_frequency_activity__minimum
- commit_frequency_codequality__minimum
- commit_frequency_without_bot_activity__minimum
- commit_frequency_without_bot_codequality__minimum
- pr_commit_count_codequality__minimum
- is_maintained_codequality__minimum
- lines_added_frequency_codequality__minimum
- LOC_frequency_codequality__minimum
- updated_since_activity__variance
- updated_since_activity__mean
- active_C2_contributor_count_codequality__minimum
- active_C2_contributor_count_activity__minimum
- is_maintained_codequality__sum_values
- lines_removed_frequency_codequality__minimum
- updated_since_activity__maximum
- code_quality_guarantee_codequality__minimum
- is_maintained_codequality__mean
- community_support_score_community__sum_values
- issue_open_time_avg_community__length
- pr_issue_linked_ratio_codequality__length
- commit_frequency_group_activity__length
- commit_frequency_without_bot_activity__length
- issue_first_reponse_mid_community__length
- active_C1_issue_create_contributor_activity__length
- community_support_score_community__length
- bug_issue_open_time_mid_community__length
- issue_open_time_mid_community__length
- pr_open_time_mid_community__length
- contribution_last_group_activity__length
- code_review_ratio_codequality__length
- contributor_count_bot_codequality__length
- bug_issue_open_time_avg_community__length
- lines_removed_frequency_codequality__length
- pr_first_response_time_avg_community__length
- commit_frequency_org_group_activity__length
- commit_frequency_without_bot_codequality__length
- commit_frequency_bot_activity__length
- code_review_count_community__length
- activity_score_activity__length
- code_merge_ratio_codequality__length
- contributor_count_without_bot_codequality__length
- code_review_count_activity__length
- commit_frequency_percentage_group_activity__length
- org_count_activity__length
- closed_issues_count_activity__length
- pr_count_codequality__length
- updated_since_activity__length
- contributor_count_without_bot_activity__length
- pr_first_response_time_mid_community__length
- org_count_group_activity__length
- comment_frequency_community__length
- recent_releases_count_activity__length
- active_C1_pr_create_contributor_codequality__length
- contributor_count_activity__length
- active_C2_contributor_count_activity__length
- updated_issues_count_activity__length
- updated_issues_count_community__length
- is_maintained_codequality__length
- active_C1_pr_comments_contributor_activity__length
- comment_frequency_activity__length
- active_C1_pr_create_contributor_activity__length
- code_quality_guarantee_codequality__length
- contributor_count_codequality__length
- commit_frequency_inside_codequality__length
- contributor_count_group_activity__length
- contributor_count_without_bot_group_activity__length
- contributor_count_bot_group_activity__length
- commit_frequency_codequality__length
- git_pr_linked_ratio_codequality__length
- commit_frequency_inside_without_bot_codequality__length
- commit_frequency_inside_bot_codequality__length
- commit_frequency_bot_codequality__length
- active_C1_pr_comments_contributor_codequality__length
- commit_frequency_bot_group_activity__length
- contributor_count_bot_activity__length
- pr_commit_count_codequality__length
- lines_added_frequency_codequality__length
- pr_open_time_avg_community__length
- commit_frequency_without_bot_group_activity__length
- contributor_org_count_group_activity__length
- issue_first_reponse_avg_community__length
- LOC_frequency_codequality__length
- active_C2_contributor_count_codequality__length
- commit_frequency_activity__length
- organizations_activity_group_activity__length
- active_C1_issue_comments_contributor_activity__length
- closed_prs_count_community__length
- pr_merged_count_codequality__length
- pr_commit_linked_count_codequality__length
- commit_frequency_org_percentage_group_activity__length
- community_support_score_community__minimum
- updated_since_activity__mean_abs_change
- activity_score_activity__sum_values
- closed_prs_count_community__minimum
- code_quality_guarantee_codequality__sum_values
- commit_frequency_org_percentage_group_activity__maximum
- activity_score_activity__minimum
- pr_merged_count_codequality__minimum
- commit_frequency_codequality__sum_values
- commit_frequency_activity__sum_values
- contributor_count_codequality__minimum
- commit_frequency_without_bot_codequality__sum_values
- commit_frequency_without_bot_activity__sum_values
- contributor_count_without_bot_codequality__minimum
- community_support_score_community__mean
- pr_commit_count_codequality__sum_values
- active_C2_contributor_count_codequality__sum_values
- active_C2_contributor_count_activity__sum_values
- closed_prs_count_community__sum_values
- pr_count_codequality__minimum
- commit_frequency_org_percentage_group_activity__mean
- commit_frequency_codequality__mean
- commit_frequency_activity__mean
- commit_frequency_without_bot_codequality__mean
- commit_frequency_without_bot_activity__mean
- activity_score_activity__mean
- contributor_org_count_group_activity__sum_values
- updated_since_activity__sum_values
- pr_count_codequality__sum_values
- pr_commit_count_codequality__mean
- commit_frequency_org_group_activity__absolute_sum_of_changes
- commit_frequency_codequality__absolute_sum_of_changes
- commit_frequency_activity__absolute_sum_of_changes
- commit_frequency_without_bot_activity__absolute_sum_of_changes
- commit_frequency_without_bot_codequality__absolute_sum_of_changes
- commit_frequency_org_group_activity__sum_values
- closed_prs_count_community__absolute_sum_of_changes
- pr_count_codequality__absolute_sum_of_changes
- closed_prs_count_community__mean
- code_quality_guarantee_codequality__mean
- active_C2_contributor_count_codequality__mean
- active_C2_contributor_count_activity__mean
- pr_merged_count_codequality__sum_values
- pr_commit_count_codequality__absolute_sum_of_changes
- pr_merged_count_codequality__absolute_sum_of_changes
- commit_frequency_org_group_activity__mean_abs_change
- pr_open_time_avg_community__variance
- commit_frequency_activity__mean_abs_change
- is_maintained_codequality__maximum
- commit_frequency_codequality__mean_abs_change
- commit_frequency_org_percentage_group_activity__last_location_of_maximum
- active_C1_pr_comments_contributor_activity__sum_values
- active_C1_pr_comments_contributor_codequality__sum_values
- commit_frequency_without_bot_activity__mean_abs_change
- commit_frequency_without_bot_codequality__mean_abs_change
- pr_open_time_mid_community__mean_abs_change
- commit_frequency_org_group_activity__mean
- pr_open_time_mid_community__variance
- pr_count_codequality__mean
- pr_open_time_avg_community__mean_abs_change
- active_C1_pr_comments_contributor_activity__minimum
- active_C1_pr_comments_contributor_codequality__minimum
- active_C1_pr_create_contributor_activity__minimum
- active_C1_pr_create_contributor_codequality__minimum
- pr_merged_count_codequality__mean
- contributor_count_codequality__sum_values
- contributor_count_without_bot_codequality__sum_values
- closed_prs_count_community__mean_abs_change
- contributor_org_count_group_activity__absolute_sum_of_changes
- pr_commit_count_codequality__mean_abs_change
- pr_merged_count_codequality__mean_abs_change
- pr_count_codequality__mean_abs_change
- code_review_count_community__sum_values
- active_C2_contributor_count_codequality__absolute_sum_of_changes
- active_C2_contributor_count_activity__absolute_sum_of_changes
- pr_count_codequality__maximum
- active_C1_pr_comments_contributor_codequality__mean
- active_C1_pr_comments_contributor_activity__mean
- commit_frequency_percentage_group_activity__mean
- closed_prs_count_community__maximum
- commit_frequency_codequality__maximum
- commit_frequency_activity__maximum
- pr_open_time_avg_community__maximum
- pr_open_time_mid_community__maximum
- commit_frequency_without_bot_activity__maximum
- commit_frequency_without_bot_codequality__maximum
- pr_merged_count_codequality__maximum
- contributor_org_count_group_activity__mean_abs_change
- active_C1_pr_create_contributor_codequality__sum_values
- active_C1_pr_create_contributor_activity__sum_values
- active_C1_pr_comments_contributor_codequality__absolute_sum_of_changes
- active_C1_pr_comments_contributor_activity__absolute_sum_of_changes
- pr_commit_count_codequality__maximum
- community_support_score_community__maximum
- closed_issues_count_activity__minimum
- pr_first_response_time_mid_community__last_location_of_minimum
- code_review_count_community__mean
- pr_open_time_mid_community__mean
- commit_frequency_org_group_activity__variance
- active_C1_pr_comments_contributor_codequality__maximum
- active_C1_pr_comments_contributor_activity__maximum
- contributor_org_count_group_activity__mean
- code_review_count_community__last_location_of_minimum
- active_C2_contributor_count_activity__maximum
- active_C2_contributor_count_codequality__maximum
- contributor_count_codequality__mean
- contributor_count_without_bot_codequality__mean
- active_C2_contributor_count_codequality__mean_abs_change
- active_C2_contributor_count_activity__mean_abs_change
- commit_frequency_org_percentage_group_activity__skewness
- code_review_ratio_codequality__last_location_of_minimum
- commit_frequency_org_group_activity__maximum
- code_review_count_activity__last_location_of_minimum
- pr_merged_count_codequality__variance
- code_merge_ratio_codequality__minimum
- activity_score_activity__skewness
- pr_count_codequality__variance
- activity_score_activity__maximum
- updated_since_activity__kurtosis
- contributor_org_count_group_activity__variance
- contributor_count_codequality__absolute_sum_of_changes
- contributor_count_without_bot_codequality__absolute_sum_of_changes
- code_review_ratio_codequality__minimum
- active_C2_contributor_count_codequality__last_location_of_minimum
- active_C2_contributor_count_activity__last_location_of_minimum
- active_C1_pr_comments_contributor_activity__mean_abs_change
- active_C1_pr_comments_contributor_codequality__mean_abs_change
- active_C1_pr_create_contributor_activity__mean
- active_C1_pr_create_contributor_codequality__mean
- code_quality_guarantee_codequality__maximum
- pr_issue_linked_ratio_codequalitylarge_standard_deviationr_0.05
- active_C1_pr_create_contributor_codequality__absolute_sum_of_changes
- active_C1_pr_create_contributor_activity__absolute_sum_of_changes
- contributor_org_count_group_activity__maximum
- pr_first_response_time_mid_community__minimum
- pr_first_response_time_avg_community__minimum
- closed_prs_count_community__variance
- pr_issue_linked_ratio_codequalitylarge_standard_deviationr_0.1
- code_review_count_activity__minimum
- commit_frequency_activity__last_location_of_minimum
- commit_frequency_codequality__last_location_of_minimum
- commit_frequency_without_bot_activity__last_location_of_minimum
- commit_frequency_without_bot_codequality__last_location_of_minimum
- code_review_count_community__minimum
- contributor_count_codequality__maximum
- contributor_count_without_bot_codequality__maximum
- pr_open_time_mid_community__absolute_sum_of_changes
- lines_removed_frequency_codequality__sum_values
- commit_frequency_codequality__variance
- commit_frequency_activity__variance
- commit_frequency_percentage_group_activity__last_location_of_maximum
- commit_frequency_without_bot_codequality__variance
- LOC_frequency_codequality__sum_values
- commit_frequency_without_bot_activity__variance
- contributor_count_activity__minimum
- contributor_count_without_bot_activity__minimum
- lines_added_frequency_codequality__sum_values
- code_review_count_activity__sum_values
- lines_removed_frequency_codequality__absolute_sum_of_changes
- code_review_count_community__absolute_sum_of_changes
- bug_issue_open_time_mid_community__last_location_of_minimum
- pr_first_response_time_avg_community__last_location_of_minimum
- updated_since_activity__mean_change
- closed_issues_count_activity__sum_values
- pr_issue_linked_ratio_codequality__sum_values
- pr_commit_linked_count_codequality__absolute_sum_of_changes
- active_C1_pr_comments_contributor_activity__variance
- active_C1_pr_comments_contributor_codequality__variance
- LOC_frequency_codequality__absolute_sum_of_changes
- lines_added_frequency_codequality__absolute_sum_of_changes
- pr_commit_count_codequality__variance
- updated_issues_count_activity__sum_values
- updated_issues_count_community__sum_values
- pr_commit_linked_count_codequality__sum_values
- bug_issue_open_time_avg_community__last_location_of_minimum
- pr_issue_linked_ratio_codequality__mean
- active_C1_issue_create_contributor_activity__minimum
- recent_releases_count_activity__minimum
- active_C1_pr_create_contributor_activity__maximum
- active_C1_pr_create_contributor_codequality__maximum
- lines_removed_frequency_codequality__mean
- updated_issues_count_activity__minimum
- updated_issues_count_community__minimum
- LOC_frequency_codequality__mean
- lines_added_frequency_codequality__mean
- code_review_ratio_codequality__sum_values
- lines_removed_frequency_codequality__mean_abs_change
- updated_since_activity__last_location_of_minimum
- pr_issue_linked_ratio_codequality__absolute_sum_of_changes
- code_review_count_community__maximum
- pr_commit_linked_count_codequality__maximum
- pr_issue_linked_ratio_codequality__mean_abs_change
- code_review_count_activity__mean
- pr_commit_linked_count_codequality__mean_abs_change
- LOC_frequency_codequality__mean_abs_change
- updated_issues_count_community__absolute_sum_of_changes
- updated_issues_count_activity__absolute_sum_of_changes
- contributor_count_without_bot_activity__sum_values
- contributor_count_activity__sum_values
- lines_added_frequency_codequality__mean_abs_change
- pr_open_time_avg_community__absolute_sum_of_changes
- active_C1_pr_comments_contributor_codequality__last_location_of_minimum
- active_C1_pr_comments_contributor_activity__last_location_of_minimum
- pr_issue_linked_ratio_codequality__first_location_of_maximum
- pr_issue_linked_ratio_codequality__last_location_of_maximum
- comment_frequency_activity__minimum
- comment_frequency_community__minimum
- pr_commit_count_codequality__last_location_of_minimum
- active_C1_issue_comments_contributor_activity__minimum
- pr_commit_linked_count_codequality__mean
- pr_open_time_avg_community__mean
- updated_since_activity__skewness
- contributor_count_codequality__mean_abs_change
- contributor_count_without_bot_codequality__mean_abs_change
- pr_open_time_mid_community__sum_values
- active_C1_issue_create_contributor_activity__sum_values
- pr_issue_linked_ratio_codequality__last_location_of_minimum
- lines_removed_frequency_codequality__maximum
- closed_issues_count_activity__absolute_sum_of_changes
- code_review_count_community__mean_abs_change
- pr_issue_linked_ratio_codequality__variance
- commit_frequency_percentage_group_activity__skewness
- active_C1_pr_create_contributor_codequality__mean_abs_change
- active_C1_pr_create_contributor_activity__mean_abs_change
- updated_since_activity__absolute_sum_of_changes
- pr_commit_linked_count_codequality__variance
- pr_issue_linked_ratio_codequality__maximum
- closed_issues_count_activity__mean
- LOC_frequency_codequality__maximum
- pr_first_response_time_avg_community__first_location_of_minimum
- issue_open_time_avg_community__variance
- active_C1_issue_create_contributor_activity__absolute_sum_of_changes
- code_review_count_activity__first_location_of_minimum
- code_review_count_community__first_location_of_minimum
- active_C2_contributor_count_activity__variance
- active_C2_contributor_count_codequality__variance
- code_quality_guarantee_codequality__variance
- pr_issue_linked_ratio_codequality__first_location_of_minimum
- lines_added_frequency_codequality__maximum
- lines_removed_frequency_codequality__variance
- code_merge_ratio_codequality__last_location_of_minimum
- active_C1_issue_comments_contributor_activity__sum_values
- commit_frequency_percentage_group_activity__absolute_sum_of_changes
- issue_open_time_mid_community__variance
- code_review_ratio_codequality__first_location_of_minimum
- bug_issue_open_time_avg_community__minimum
- updated_issues_count_activity__mean
- updated_issues_count_community__mean
- code_review_ratio_codequality__mean
- updated_since_activity__minimum
- LOC_frequency_codequality__variance
- issue_open_time_avg_community__mean_abs_change
- activity_score_activity__mean_change
- bug_issue_open_time_mid_community__minimum
- issue_open_time_avg_community__maximum
- is_maintained_codequalitylarge_standard_deviationr_0.1
- contributor_count_without_bot_activity__absolute_sum_of_changes
- updated_issues_count_activity__last_location_of_minimum
- updated_issues_count_community__last_location_of_minimum
- contributor_count_activity__absolute_sum_of_changes
- issue_first_reponse_mid_community__mean_abs_change
- lines_added_frequency_codequality__variance
- code_quality_guarantee_codequality__mean_abs_change
- issue_open_time_mid_community__mean_abs_change
- is_maintained_codequalitylarge_standard_deviationr_0.05
- issue_open_time_mid_community__maximum
- pr_commit_linked_count_codequality__minimum
- recent_releases_count_activity__sum_values
- pr_first_response_time_mid_community__first_location_of_minimum
- issue_first_reponse_mid_community__variance
- community_support_score_community__mean_abs_change
- is_maintained_codequality__last_location_of_maximum
- pr_merged_count_codequality__last_location_of_minimum
- updated_issues_count_activity__maximum
- updated_issues_count_community__maximum
- recent_releases_count_activity__absolute_sum_of_changes
- issue_first_reponse_avg_community__mean_abs_change
- contributor_count_activity__mean
- contributor_count_without_bot_activity__mean
- active_C1_issue_comments_contributor_activity__absolute_sum_of_changes
- code_review_count_activity__absolute_sum_of_changes
- active_C1_issue_create_contributor_activity__mean
- issue_first_reponse_mid_community__maximum
- closed_issues_count_activity__maximum
- code_review_count_activitylarge_standard_deviationr_0.05
- code_review_count_activitylarge_standard_deviationr_0.1
- code_review_count_communitylarge_standard_deviationr_0.05
- code_review_count_communitylarge_standard_deviationr_0.1
- recent_releases_count_activity__mean
- closed_issues_count_activity__mean_abs_change
- contributor_count_codequality__variance
- contributor_count_without_bot_codequality__variance
- code_review_ratio_codequalitylarge_standard_deviationr_0.05
- code_review_ratio_codequalitylarge_standard_deviationr_0.1
- pr_first_response_time_avg_communitylarge_standard_deviationr_0.1
- commit_frequency_org_percentage_group_activity__absolute_sum_of_changes
- pr_first_response_time_mid_communitylarge_standard_deviationr_0.05
- pr_first_response_time_avg_communitylarge_standard_deviationr_0.05
- issue_first_reponse_avg_community__last_location_of_maximum
- pr_first_response_time_mid_communitylarge_standard_deviationr_0.1
- code_merge_ratio_codequality__first_location_of_maximum
- community_support_score_community__variance
- code_merge_ratio_codequality__variance
- contributor_count_without_bot_group_activity__absolute_sum_of_changes
- recent_releases_count_activity__maximum
- issue_first_reponse_mid_community__mean
- commit_frequency_org_percentage_group_activity__sum_values
- contributor_count_group_activity__absolute_sum_of_changes
- updated_issues_count_activity__mean_abs_change
- updated_issues_count_community__mean_abs_change
- active_C1_pr_create_contributor_activity__variance
- active_C1_pr_create_contributor_codequality__variance
- closed_prs_count_community__last_location_of_minimum
- org_count_group_activity__sum_values
- org_count_activity__sum_values
- contributor_count_group_activity__sum_values
- contributor_count_without_bot_group_activity__sum_values
- organizations_activity_group_activity__sum_values
- comment_frequency_community__sum_values
- comment_frequency_activity__sum_values
- contributor_count_group_activity__maximum
- contributor_count_without_bot_group_activity__maximum
- recent_releases_count_activity__mean_abs_change
- contribution_last_group_activity__sum_values
- org_count_group_activity__maximum
- org_count_activity__maximum
- active_C1_issue_create_contributor_activity__maximum
- pr_issue_linked_ratio_codequality__skewness
- community_support_score_community__mean_change
- activity_score_activity__absolute_sum_of_changes
- code_review_count_community__first_location_of_maximum
- organizations_activity_group_activity__absolute_sum_of_changes
- organizations_activity_group_activity__maximum
- active_C1_issue_comments_contributor_activity__mean
- git_pr_linked_ratio_codequality__last_location_of_maximum
- contributor_count_without_bot_activity__maximum
- contributor_count_activity__maximum
- issue_first_reponse_avg_community__variance
- bug_issue_open_time_avg_community__sum_values
- contribution_last_group_activity__absolute_sum_of_changes
- org_count_group_activity__absolute_sum_of_changes
- commit_frequency_org_percentage_group_activity__first_location_of_maximum
- org_count_activity__absolute_sum_of_changes
- contribution_last_group_activity__maximum
- contributor_count_without_bot_group_activity__mean_abs_change
- org_count_group_activity__mean
- org_count_activity__mean
- contributor_count_group_activity__mean
- code_review_count_activity__maximum
- contributor_count_without_bot_group_activity__mean
- contributor_count_group_activity__mean_abs_change
- issue_first_reponse_mid_community__absolute_sum_of_changes
- commit_frequency_group_activity__absolute_sum_of_changes
- organizations_activity_group_activity__mean
- commit_frequency_without_bot_group_activity__absolute_sum_of_changes
- commit_frequency_group_activity__sum_values
- commit_frequency_without_bot_group_activity__sum_values
- lines_removed_frequency_codequality__last_location_of_minimum
- active_C1_pr_comments_contributor_codequality__first_location_of_minimum
- active_C1_pr_comments_contributor_activity__first_location_of_minimum
- contributor_count_group_activity__variance
- contributor_count_without_bot_group_activity__variance
- contribution_last_group_activity__mean
- pr_open_time_avg_community__minimum
- lines_added_frequency_codequality__last_location_of_minimum
- issue_first_reponse_avg_community__maximum
- code_review_count_activity__mean_abs_change
- commit_frequency_group_activity__maximum
- commit_frequency_without_bot_group_activity__maximum
- active_C1_issue_create_contributor_activity__mean_abs_change
- issue_first_reponse_avg_community__first_location_of_minimum
- updated_issues_count_activity__mean_change
- updated_issues_count_community__mean_change
- commit_frequency_group_activity__mean
- commit_frequency_group_activity__mean_abs_change
- commit_frequency_without_bot_group_activity__mean
- commit_frequency_without_bot_group_activity__mean_abs_change
- code_merge_ratio_codequality__last_location_of_maximum
- pr_commit_linked_count_codequality__last_location_of_minimum
- updated_issues_count_activity__variance
- updated_issues_count_community__variance
- commit_frequency_percentage_group_activity__mean_abs_change
- contribution_last_group_activity__mean_abs_change
- commit_frequency_without_bot_group_activity__last_location_of_minimum
- organizations_activity_group_activity__last_location_of_minimum
- closed_issues_count_activity__last_location_of_minimum
- commit_frequency_group_activity__last_location_of_minimum
- commit_frequency_group_activity__variance
- commit_frequency_without_bot_group_activity__variance
- LOC_frequency_codequality__last_location_of_minimum
- pr_first_response_time_mid_community__first_location_of_maximum
- active_C1_issue_comments_contributor_activity__maximum
- code_review_count_community__variance
- issue_open_time_mid_community__mean
- org_count_group_activity__mean_abs_change
- org_count_activity__mean_abs_change
- organizations_activity_group_activity__mean_abs_change
- contribution_last_group_activity__variance
- recent_releases_count_activity__last_location_of_minimum
- contributor_count_codequality__last_location_of_minimum
- is_maintained_codequality__variance
- pr_first_response_time_avg_community__last_location_of_maximum
- contributor_count_without_bot_codequality__last_location_of_minimum
- org_count_group_activity__variance
- org_count_activity__variance
- contributor_count_group_activity__last_location_of_minimum
- commit_frequency_without_bot_group_activitylarge_standard_deviationr_0.1
- commit_frequency_group_activitylarge_standard_deviationr_0.1
- pr_count_codequality__last_location_of_minimum
- commit_frequency_group_activitylarge_standard_deviationr_0.05
- commit_frequency_without_bot_group_activitylarge_standard_deviationr_0.05
- contributor_count_without_bot_group_activitylarge_standard_deviationr_0.1
- contributor_count_group_activitylarge_standard_deviationr_0.1
- git_pr_linked_ratio_codequality__maximum
- contributor_count_without_bot_group_activity__last_location_of_minimum
- issue_first_reponse_mid_community__sum_values
- contribution_last_group_activity__minimum
- commit_frequency_org_percentage_group_activity__minimum
- organizations_activity_group_activitylarge_standard_deviationr_0.1
- contribution_last_group_activity__last_location_of_minimum
- recent_releases_count_activity__variance
- commit_frequency_without_bot_group_activity__first_location_of_minimum
- contributor_count_group_activitylarge_standard_deviationr_0.05
- contributor_count_without_bot_group_activitylarge_standard_deviationr_0.05
- bug_issue_open_time_avg_community__mean
- is_maintained_codequality__mean_abs_change
- contribution_last_group_activitylarge_standard_deviationr_0.1
- contribution_last_group_activitylarge_standard_deviationr_0.05
- organizations_activity_group_activitylarge_standard_deviationr_0.05
- commit_frequency_group_activity__first_location_of_minimum
- code_merge_ratio_codequality__maximum
- contributor_org_count_group_activitylarge_standard_deviationr_0.05
- organizations_activity_group_activity__minimum
- contributor_count_group_activity__minimum
- closed_issues_count_activity__variance
- org_count_activity__minimum
- org_count_group_activity__minimum
- commit_frequency_group_activity__minimum
- commit_frequency_percentage_group_activity__first_location_of_maximum
- git_pr_linked_ratio_codequality__minimum
- contributor_org_count_group_activitylarge_standard_deviationr_0.1
- issue_first_reponse_avg_community__mean
- organizations_activity_group_activity__first_location_of_minimum
- is_maintained_codequality__skewness
- contributor_count_without_bot_activity__mean_abs_change
- contributor_count_bot_activity__sum_values
- org_count_activitylarge_standard_deviationr_0.1
- org_count_group_activitylarge_standard_deviationr_0.1
- contributor_count_activity__mean_abs_change
- pr_merged_count_codequality__first_location_of_maximum
- community_support_score_community__last_location_of_minimum
- git_pr_linked_ratio_codequality__variance
- issue_first_reponse_avg_community__absolute_sum_of_changes
- contribution_last_group_activity__first_location_of_minimum
- bug_issue_open_time_mid_community__sum_values
- comment_frequency_activity__variance
- comment_frequency_community__variance
- code_review_count_activity__variance
- commit_frequency_without_bot_group_activity__last_location_of_maximum
- commit_frequency_group_activity__last_location_of_maximum
- contributor_count_without_bot_group_activity__minimum
- contributor_org_count_group_activity__last_location_of_minimum
- bug_issue_open_time_avg_community__first_location_of_minimum
- pr_first_response_time_avg_community__sum_values
- org_count_activitylarge_standard_deviationr_0.05
- org_count_group_activitylarge_standard_deviationr_0.05
- commit_frequency_without_bot_group_activity__minimum
- commit_frequency_percentage_group_activity__sum_values
- commit_frequency_percentage_group_activity__minimum
- contributor_count_without_bot_group_activity__first_location_of_minimum
- code_review_ratio_codequality__last_location_of_maximum
- org_count_group_activity__last_location_of_minimum
- org_count_activity__last_location_of_minimum
- code_review_ratio_codequality__first_location_of_maximum
- contributor_count_group_activity__first_location_of_minimum
- contributor_count_bot_activity__mean
- commit_frequency_org_group_activity__first_location_of_maximum
- active_C1_issue_comments_contributor_activity__mean_abs_change
- recent_releases_count_activity__first_location_of_maximum
- code_merge_ratio_codequality__sum_values
- contributor_count_without_bot_group_activity__first_location_of_maximum
- contributor_count_group_activity__first_location_of_maximum
- active_C1_pr_comments_contributor_activitylarge_standard_deviationr_0.05
- active_C1_pr_comments_contributor_codequalitylarge_standard_deviationr_0.05
- active_C1_pr_comments_contributor_activitylarge_standard_deviationr_0.1
- active_C1_pr_comments_contributor_codequalitylarge_standard_deviationr_0.1
- commit_frequency_percentage_group_activitylarge_standard_deviationr_0.05
- active_C1_pr_create_contributor_codequality__last_location_of_minimum
- active_C1_pr_create_contributor_activity__last_location_of_minimum
- bug_issue_open_time_mid_communitylarge_standard_deviationr_0.05
- bug_issue_open_time_mid_communitylarge_standard_deviationr_0.1
- bug_issue_open_time_avg_communitylarge_standard_deviationr_0.05
- bug_issue_open_time_avg_communitylarge_standard_deviationr_0.1
- activity_score_activity__last_location_of_minimum
- contributor_count_bot_activity__maximum
- bug_issue_open_time_mid_community__first_location_of_maximum
- contributor_org_count_group_activity__first_location_of_maximum
- organizations_activity_group_activity__first_location_of_maximum
- commit_frequency_without_bot_group_activity__first_location_of_maximum
- code_review_count_activity__first_location_of_maximum
- commit_frequency_group_activity__first_location_of_maximum
- bug_issue_open_time_mid_community__first_location_of_minimum
- commit_frequency_org_percentage_group_activitylarge_standard_deviationr_0.1
- commit_frequency_org_percentage_group_activitylarge_standard_deviationr_0.05
- pr_open_time_mid_community__minimum
- organizations_activity_group_activity**last_location_of_maximum
A.2 Feature Set 2 (Comprising 134 features, named as: Index Name__Feature Function)
- commit_frequency_activity__minimum
- commit_frequency_codequality__minimum
- commit_frequency_without_bot_activity__minimum
- commit_frequency_without_bot_codequality__minimum
- pr_commit_count_codequality__minimum
- is_maintained_codequality__minimum
- lines_added_frequency_codequality__minimum
- LOC_frequency_codequality__minimum
- updated_since_activity__variance
- updated_since_activity__mean
- active_C2_contributor_count_codequality__minimum
- active_C2_contributor_count_activity__minimum
- is_maintained_codequality__sum_values
- lines_removed_frequency_codequality__minimum
- updated_since_activity__maximum
- code_quality_guarantee_codequality__minimum
- is_maintained_codequality__mean
- community_support_score_community__sum_values
- issue_open_time_avg_community__length
- pr_issue_linked_ratio_codequality__length
- commit_frequency_group_activity__length
- commit_frequency_without_bot_activity__length
- issue_first_reponse_mid_community__length
- active_C1_issue_create_contributor_activity__length
- community_support_score_community__length
- bug_issue_open_time_mid_community__length
- issue_open_time_mid_community__length
- pr_open_time_mid_community__length
- contribution_last_group_activity__length
- code_review_ratio_codequality__length
- contributor_count_bot_codequality__length
- bug_issue_open_time_avg_community__length
- lines_removed_frequency_codequality__length
- pr_first_response_time_avg_community__length
- commit_frequency_org_group_activity__length
- commit_frequency_without_bot_codequality__length
- commit_frequency_bot_activity__length
- code_review_count_community__length
- activity_score_activity__length
- code_merge_ratio_codequality__length
- contributor_count_without_bot_codequality__length
- code_review_count_activity__length
- commit_frequency_percentage_group_activity__length
- org_count_activity__length
- closed_issues_count_activity__length
- pr_count_codequality__length
- updated_since_activity__length
- contributor_count_without_bot_activity__length
- pr_first_response_time_mid_community__length
- org_count_group_activity__length
- comment_frequency_community__length
- recent_releases_count_activity__length
- active_C1_pr_create_contributor_codequality__length
- contributor_count_activity__length
- active_C2_contributor_count_activity__length
- updated_issues_count_activity__length
- updated_issues_count_community__length
- is_maintained_codequality__length
- active_C1_pr_comments_contributor_activity__length
- comment_frequency_activity__length
- active_C1_pr_create_contributor_activity__length
- code_quality_guarantee_codequality__length
- contributor_count_codequality__length
- commit_frequency_inside_codequality__length
- contributor_count_group_activity__length
- contributor_count_without_bot_group_activity__length
- contributor_count_bot_group_activity__length
- commit_frequency_codequality__length
- git_pr_linked_ratio_codequality__length
- commit_frequency_inside_without_bot_codequality__length
- commit_frequency_inside_bot_codequality__length
- commit_frequency_bot_codequality__length
- active_C1_pr_comments_contributor_codequality__length
- commit_frequency_bot_group_activity__length
- contributor_count_bot_activity__length
- pr_commit_count_codequality__length
- lines_added_frequency_codequality__length
- pr_open_time_avg_community__length
- commit_frequency_without_bot_group_activity__length
- contributor_org_count_group_activity__length
- issue_first_reponse_avg_community__length
- LOC_frequency_codequality__length
- active_C2_contributor_count_codequality__length
- commit_frequency_activity__length
- organizations_activity_group_activity__length
- active_C1_issue_comments_contributor_activity__length
- closed_prs_count_community__length
- pr_merged_count_codequality__length
- pr_commit_linked_count_codequality__length
- commit_frequency_org_percentage_group_activity__length
- community_support_score_community__minimum
- updated_since_activity__mean_abs_change
- activity_score_activity__sum_values
- closed_prs_count_community__minimum
- code_quality_guarantee_codequality__sum_values
- commit_frequency_org_percentage_group_activity__maximum
- activity_score_activity__minimum
- pr_merged_count_codequality__minimum
- commit_frequency_codequality__sum_values
- commit_frequency_activity__sum_values
- contributor_count_codequality__minimum
- commit_frequency_without_bot_codequality__sum_values
- commit_frequency_without_bot_activity__sum_values
- contributor_count_without_bot_codequality__minimum
- community_support_score_community__mean
- pr_commit_count_codequality__sum_values
- active_C2_contributor_count_codequality__sum_values
- active_C2_contributor_count_activity__sum_values
- closed_prs_count_community__sum_values
- pr_count_codequality__minimum
- commit_frequency_org_percentage_group_activity__mean
- commit_frequency_codequality__mean
- commit_frequency_activity__mean
- commit_frequency_without_bot_codequality__mean
- commit_frequency_without_bot_activity__mean
- activity_score_activity__mean
- contributor_org_count_group_activity__sum_values
- updated_since_activity__sum_values
- pr_count_codequality__sum_values
- pr_commit_count_codequality__mean
- commit_frequency_org_group_activity__absolute_sum_of_changes
- commit_frequency_codequality__absolute_sum_of_changes
- commit_frequency_activity__absolute_sum_of_changes
- commit_frequency_without_bot_activity__absolute_sum_of_changes
- commit_frequency_without_bot_codequality__absolute_sum_of_changes
- commit_frequency_org_group_activity__sum_values
- closed_prs_count_community__absolute_sum_of_changes
- pr_count_codequality__absolute_sum_of_changes
- closed_prs_count_community__mean
- code_quality_guarantee_codequality__mean
- active_C2_contributor_count_codequality__mean
- active_C2_contributor_count_activity__mean
- pr_merged_count_codequality__sum_values
- pr_commit_count_codequality__absolute_sum_of_changes
Appendix B: Indices for Feature Extraction
Four aspects encompassing 72 indices were involved in the computation of features:
B.1 Indices Related to Activity
- contributor_count_activity,
- contributor_count_bot_activity,
- contributor_count_without_bot_activity,
- active_C2_contributor_count_activity,
- active_C1_pr_create_contributor_activity,
- active_C1_pr_comments_contributor_activity,
- active_C1_issue_create_contributor_activity,
- active_C1_issue_comments_contributor_activity,
- commit_frequency_activity,
- commit_frequency_bot_activity,
- commit_frequency_without_bot_activity,
- org_count_activity,
- comment_frequency_activity,
- code_review_count_activity,
- updated_since_activity,
- closed_issues_count_activity,
- updated_issues_count_activity,
- recent_releases_count_activity,
- activity_score_activity,
B.2 Indices Related to Code Quality Assurance
- contributor_count_codequality,
- contributor_count_bot_codequality,
- contributor_count_without_bot_codequality,
- active_C2_contributor_count_codequality,
- active_C1_pr_create_contributor_codequality,
- active_C1_pr_comments_contributor_codequality,
- commit_frequency_codequality,
- commit_frequency_bot_codequality,
- commit_frequency_without_bot_codequality,
- commit_frequency_inside_codequality,
- commit_frequency_inside_bot_codequality,
- commit_frequency_inside_without_bot_codequality,
- is_maintained_codequality,
- LOC_frequency_codequality,
- lines_added_frequency_codequality,
- lines_removed_frequency_codequality,
- pr_issue_linked_ratio_codequality,
- code_review_ratio_codequality,
- code_merge_ratio_codequality,
- pr_count_codequality,
- pr_merged_count_codequality,
- pr_commit_count_codequality,
- pr_commit_linked_count_codequality,
- git_pr_linked_ratio_codequality,
- code_quality_guarantee_codequality,
B.3 Indices Related to Community Service and Support
- issue_first_reponse_avg_community,
- issue_first_reponse_mid_community,
- issue_open_time_avg_community,
- issue_open_time_mid_community,
- bug_issue_open_time_avg_community,
- bug_issue_open_time_mid_community,
- pr_open_time_avg_community,
- pr_open_time_mid_community,
- pr_first_response_time_avg_community,
- pr_first_response_time_mid_community,
- comment_frequency_community,
- code_review_count_community,
- updated_issues_count_community,
- closed_prs_count_community,
- community_support_score_community,
B.4 Indices Related to Collaborative Development
- contributor_count_group_activity,
- contributor_count_bot_group_activity,
- contributor_count_without_bot_group_activity,
- contributor_org_count_group_activity,
- commit_frequency_group_activity,
- commit_frequency_bot_group_activity,
- commit_frequency_without_bot_group_activity,
- commit_frequency_org_group_activity,
- commit_frequency_org_percentage_group_activity,
- commit_frequency_percentage_group_activity,
- org_count_group_activity,
- contribution_last_group_activity,
- organizations_activity_group_activity
Appendix C: 16 Feature Functions
length (Length): This function calculates the length of the dataset, i.e., the number of data points or samples contained.
large_standard_deviation (Large Standard Deviation): Detects the proportion of values in the data that are greater than a given standard deviation. Different threshold values (r values) can be set to determine what constitutes a large standard deviation.
mean (Mean): Calculates the average of all data points in the dataset.
maximum (Maximum): Identifies the maximum value in the dataset.
minimum (Minimum): Identifies the minimum value in the dataset.
sum_values (Sum of Values): Computes the total sum of all data points in the dataset.
variance (Variance): Measures the variance of the dataset, indicating the degree of dispersion of the data points from the mean.
skewness (Skewness): Skewness measures the degree of asymmetry of data distribution, indicating whether the data is left-skewed (negative skewness) or right-skewed (positive skewness).
kurtosis (Kurtosis): Kurtosis assesses the peakedness or flatness of the data distribution, reflecting the shape of the distribution.
absolute_sum_of_changes (Absolute Sum of Changes): Calculates the sum of absolute changes between adjacent data points.
mean_abs_change (Mean Absolute Change): Computes the average absolute change between adjacent data points in the dataset.
mean_change (Mean Change): Calculates the average change between adjacent data points in the dataset.
first_location_of_maximum (First Location of Maximum): Identifies the first occurrence of the maximum value in the dataset.
first_location_of_minimum (First Location of Minimum): Identifies the first occurrence of the minimum value in the dataset.
last_location_of_maximum (Last Location of Maximum): Determines the last occurrence of the maximum value in the dataset.
last_location_of_minimum (Last Location of Minimum): Determines the last occurrence of the minimum value in the dataset.