基于OSS Compass指标预测开源项目活跃度
刘政,祖小岚,罗星宇,王子杭,张洁芮,王晔晖,汪亮, 陶先平 南京大学计算机科学与技术系,软件新技术全国重点实验室 华为技术有限公司 开源指南针(OSS Compass)
摘要
本方法基于 OSS Compass 指标预测开源项目的未来活跃状态。该方法采用了基于特征的时间序列分类预测方法,通过提取 OSS Compass 指标序列中的统计特征,训练并运用机器学习智能分类模型对项目未来的活跃/不活跃状态进行预测,同时给出近似概率估计。在近 600 个项目数据集上的交叉验证结果显示,该方法的准确率接近 90%。在泛化能力方面,本方法在超过一万个仓库的数据集上仍能够达到 80%的准确率,初步具备现实可用性。分析结果能够部分反映开源项目的未来健康状态,进而展示了 OSS Compass 指标体系在度量开源软件健康度上的有效性。该方法有望为开源软件的用户、开发者、投资者和管理者提供有价值的参考信息。
1 OSS Compass 开源项目健康度量指标数据集
1.1 数据准备
本研究涉及两主要数据集,旨在为我们的研究提供充分的信息支持。首先,我们拥有总体数据集 A,其中包含 20213 个仓库的信息。此数据集的规模庞大,代表了广泛的开源项目,为我们的研究提供了广泛的参考资源。其次,我们还创建了一个精心挑选的数据子集,即数据集 B。数据集 B 是从总体数据集 A 中筛选出来的,依据开源项目的星标数量、派生数量等指标,以确保它代表了开源社区中最有影响力和代表性的项目。数据集 B 包含了 735 个仓库,这些仓库的信息将成为我们研究中获取特征的关键依据。之后我们获得每个仓库的 metr 时间序列数据,这些数据共分为四个维度,共 80 个指标(包括时间列),每个指标均为时间序列,每个仓库的每个指标的时间序列一一对应(缺失数据均补 0)。
1.2 数据清洗
在对获得的 metric 数据进行深入研究后,我们进行了进一步的数据筛选步骤,以确保所使用的数据集的质量和可信度。首先,我们排除了那些数据获取存在困难的仓库,这些仓库可能由于数据不足或包含不规范的脏数据而难以分析。经过筛选后,最终的结果如下:总体数据集 A 中,剩下 20181 个仓库,数据充足,包含了我们所需的所有 metric 信息。而数据集 B 中,也经过筛选后,剩余了 600 个仓库,这些仓库在数据质量和可用性方面表现出色,为我们进一步�的分析提供了坚实的基础。
1.3 开源仓库筛选
由于预测任务对时间序列的长度有一定要求,我们采取了一系列数据筛选和处理步骤,以确保数据集的质量和适用性。首先,我们排除了时间序列长度不足的仓库,这些包括空仓库,因为它们无法提供足够的信息进行可靠的预测。此外,我们需要利用项目转变为不活跃状态之前的时间序列进行训练和预测,然而,部分项目从记录时间起就一直处于不活跃状态,这意味着时间序列中没有记录项目转变为不活跃状态的过程。因此,我们也将这些仓库剔除,以确保模型的训练和预测过程具有可行性和准确性。 在数据筛选和处理之后,我们最终得到了由 19413 个仓库组成的数据集 A 和由 585 个仓库组成的数据集 B,这些仓库的时间序列满足预测任务的要求。之后我们对仓库的活跃度进行判断,具体的判定标准参见第 1.3 节。
在数据集 A 中,有 5411 个被判定为处于活跃状态,14002 个被判定为不活跃状态,标签分布不均衡,这也与现实情况下活跃项目较少的事实相符;在数据集 B 的仓库中,有 325 个被判定为处于活跃状态,260 个被判定为不活跃状态。其标签分布相对均衡,这对于后续的预测任务非常有益,因为它有助于模型更好地学习和预测不同状态下的仓库表现。
在接下来的工作中,我们将基于这个经过精心筛选和处理的数据集展开预测和评估工作。这个数据集的质量和准确性将为我们的预测模型提供坚实的基础,使我们能够更好地理解和预测仓库的行为和状态变化。
1.4 项目活跃/不活跃判断标准
上述描述中的指标均为预测问题中的自变量,要获取因变量需要根据 inactive/active 的定义对每个仓库样本进行分析,对其打标签,从而进行训练和预测。 为了确定仓库的活跃状态(inactive/active),我们采用以下标准进行分析和标签打标:当一个仓库满足以下条件之一时,我们认为它是不活跃的:
1.仓库超过一年的时间段内没有活动。活动的定义可以包括提交(commit)、分支(branch)创建、问题(issue)跟踪、合并请求(pull request)等项目相关的操作。
2.仓库在过去一年内有活动,但提交(commit)次数较少。这意味着仓库虽然有一些活动,但活动频率极低,不足以维持其活跃状态。
根据以上定义,我们对每个仓库样本进行了分析,并进行了标签化。任何满足上述条件之一的仓库都被视为不活跃仓库,而不满足这些条件的仓库则被标记为活跃仓库。这一明确的活跃/不活跃标准将确保我们对项目状态的判断是基于客观的、可量化的指标,为后续的分析和预测提供了清晰的基础。
2 基于特征的项目活跃度预测方法
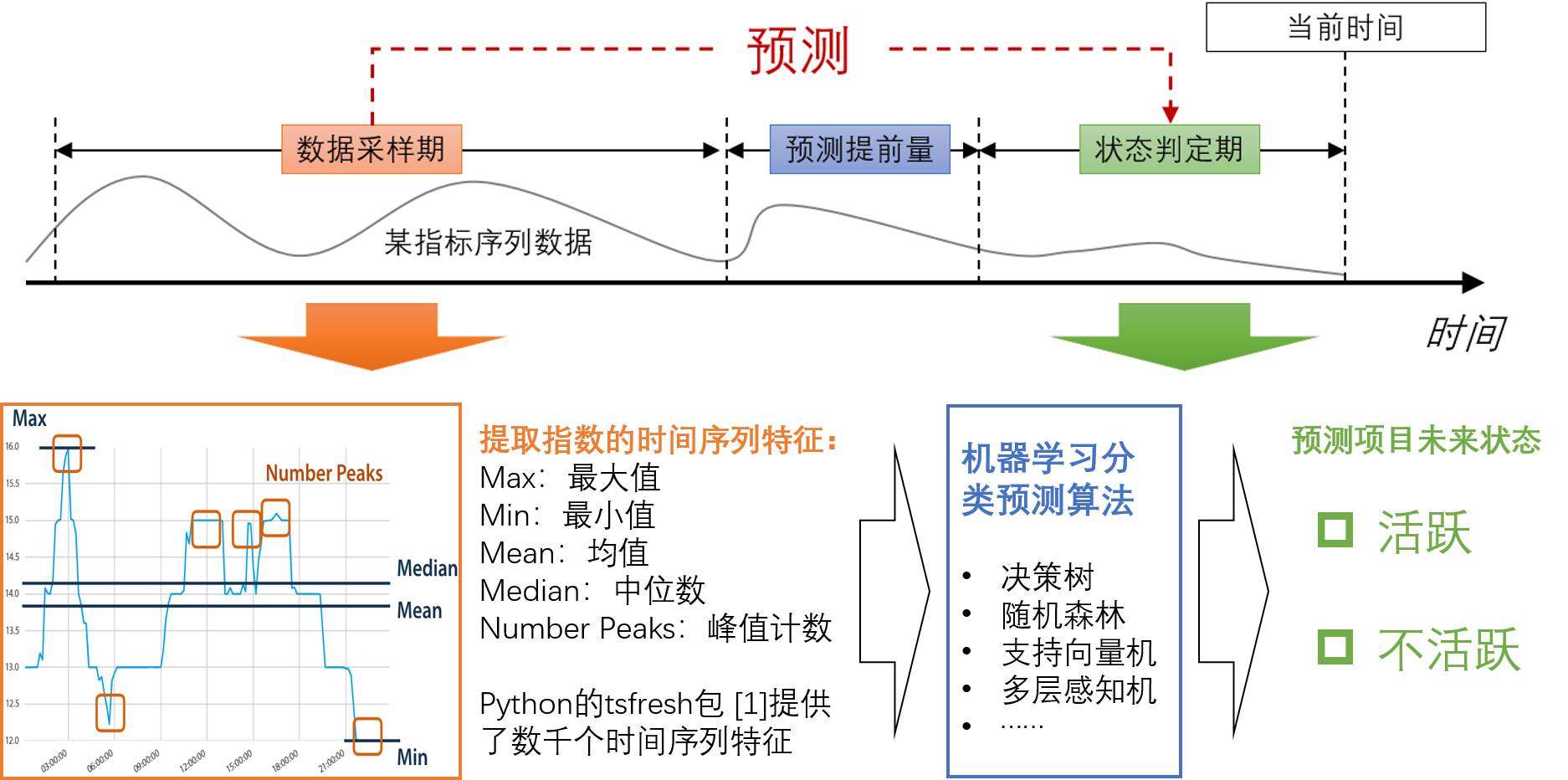
图 2-1 基于特征提取+经典机器学习技术的预测方法
如图 2-1 所示,基于特征的方法是一种经典机器学习方法,通常用于处理时间序列数据。其核心思想是将时间序列数据转化为一组特征,这些特征包括但不限于统计指标如平均数、中位数、最大值、最小值、方差等。通过提取这些特征,我们可以将原始的时间序列数据转换成一个非时间序列的 CSV 数据表格,从而可以采用 KNN、决策树等传统的数据分析和机器学习技术来处理和分析这些数据。这种方法的优势在于它能够简化复杂的时间序列数据,将其转化为具有固定维度的特征向量,从而方便了后续的数据处理和建模过程。此外,特征提取还可以帮助减少数据中的噪声和冗余信息,提高模型的稳定性和性能。在基于特征的方法中,通常会采取以下步骤:
1.数据采集:首先,收集时间序列数据,这可以是来自传感器、金融市场、气象站点或其他领域的数据。
2.特征提取:对时间序列数据进行特征提取,这包括计算各种统计指标,如均值、中位数、标准差、峰度、偏度等。此外,还可以使用信号处理技术来提取频域特征,如傅里叶变换、小波变换等。
3.数据转换:将提取的特征组成一个表格形式的数据集,通常保存为 CSV 文件。每一行代表一个时间序列样本,而每一列代表一个特征。
4.数据预处理:对数据进行预处理,包括缺失值处理、标准化、归一化等操作,以确保数据在建模过程中的稳定性和可用性。
5.建模与分析:使用传统的机器学习算法,如线性回归、决策树、随机森林、支持向量机等,对特征化的数据进行建模和分析。
6.模型评估:评估模型的性能,通常采用交叉验证、指标如准确度、均方误差、ROC 曲线等来评估模型的效果。
在上述步骤中,比较关键的步骤包括特征提取和学习算法的设计�两个方面,详细介绍如下。
2.1 提取的特征集合
在本工作中,我们对包括 4 个方面,共 72 个指数进行了特征提取,其中包括:
-
活跃度(Activity Score)相关指标,如 active_C2_contributor_count_activity、 active_C1_pr_create_contributor_activity 等共 19 个指标,参见附录 D.1。
-
代码质量保障(Code Quality Guarantee)相关指标,包括 contributor_count_codequality、contributor_count_bot_codequality 等共 25 个指标,参见附录 D.2。
-
社区服务与支撑(Community Service and Support)指标,包括 issue_first_reponse_avg_community、issue_first_reponse_mid_community 等共 15 个指标,参见附录 D.3。
-
协作开发指数(Group Activity)相关指标,如 contributor_count_group_activity、contributor_count_bot_group_activity 等共 13 个指标,参见附录 D.4。
除此以外,项目的基本信息,如,项目名称和 grimoire_creation_date 等也参与了特征的运算,但由于这些信息不属于 OSS Compass 所提出的指标和指标模型,我们不对这些信息开展特征提取。针对上述 72 个指数中的数值特征,我们选取了多个统计意义上的函数,包括长度(length), 标准差(large_standard_deviation),平均值(mean),最大值(maximum),最小值(minimum),方差(variance)等有代表性的统计量共 16 个(具体请参见附录 E),对上述指标数据进行了计算获得了相应的特征向量。进一步地,我们根据不同分类器的偏好,通过特征选择挑选了两组较为典型的特征集合:
-
特征组 1:包括 596 个不同的特征,用于 XGBoost,RandomForest,AdaBoost 等分类器。
-
特征组 2:包括 134 个特征,用于 KNN,Logistic,SVM 等分类器。
上述两组特征集合的具体内容可参见附录 B。
2.2 分类预测算法
-
XGBoost(极端梯度提升):XGBoost 通过组合多个决策树来提高模型性能,具有出色的准确性和鲁棒性。XGBoost 通过优化损失函数来逐步改进模型,防止过拟合,并支持特征选择。它被广泛用于 Kaggle 竞赛等数据科学任务。
-
RandomForest(随机森林):RandomForest 是一种集成学习方法,基于多个决策树的投票结果进行分类或回归。它通过引入随机性来减少过拟合风险,具有良好的泛化能力和对特征的自动选择。RandomForest 适用于各种数据类型,易于使用,并且不需要太多的超参数调整。
-
AdaBoost(自适应增强):AdaBoost 是一种迭代学习算法,通过组合多个弱学习器来提高模型性能。它根据前一轮学习的错误来调整样本权重,使错误分类的样本受到更多关注。AdaBoost 通常用于二分类问题,适用于各种分类器。在本项目中,我们使用决策树作为基学习器,记为 AdaBoost + DecisionTree。
-
Logistic Regression(逻辑回归):Logistic 回归是一种广泛应用于分类问题的线性模型。它使用逻辑函数来估计输入特征与二元目标之间的关系。Logistic 回归简单,易于解释,通常用于预测概率性事件,如客户流失或疾病诊断。
-
SVM(支持向量机):SVM 是一种用于分类和回归的强大算法。它通过寻找最佳超平面来最大化不同类别�之间的间隔。SVM 在高维空间中表现良好,可以使用不同的核函数来适应不同类型的数据。
-
KNN(K 最近邻):KNN 是一种基于实例的学习算法,用于分类和回归。它通过测量与待预测点最近的 K 个邻居来进行决策。KNN 简单且易于理解,但对于大型数据集可能效率较低。
建立在大量经典的机器学习算法的基础之上,基于特征的分类预测方法具有方法多样、实现简便、工具丰富等优势;同时,通过提取具有明确物理含义的特征集合来刻画项目,基于特征的方法具备较高的可解释性。
3 实证研究设计和结果
本节基于所上述方法设计,通过开展实证研究,验证在机器学习和人工智能方法的支撑下,OSS Compass 指标体系预测项目未来是否活跃与健康的有效性。
3.1 实证研究方法学
本节首先介绍实证研究所使用的数据集、方法和评价指标。
3.1.1 数据集
我们共使用两个数据集:数据集 A 和数据集 B。
首先我们先在数据集 B 上训练和预测,并且观察到良好的性能表现。
然后我们把该模型应用到数据集 A 中,它帮助我们评估模型的泛化能力,即模型在未曾见过的真实世界情境��中的表现如何。
3.1.2 验证方法
- 十折交叉验证方法:
通过采用十折交叉验证方法,我们在评估我们的分类模型性能时确保了充分的鲁棒性和泛化能力。我们将数据集分为十个子集,然后选取其中九个作为训练集训练模型,剩下的一个子集作为测试集测试模型,并重复以上操作十次,以消除随机性对性能评估的影响。这种方法帮助我们更可靠地了解模型在不同数据子集上的表现,并避免了过拟合的问题。
- 特征选择实验方法:
通过利用 Tsfresh 的 select_features 函数,并调整 fdr_level 参数,我们得到了一个经过精心挑选的特征集合。这些特征在分类任务中发挥了显著作用,有助于提高模型的性能。我们的选择是基于统计显著性进行的,FDR(False Discovery Rate)控制了特征选择的严格性,较低的 fdr_level 值确保高度显著的特征将被选择,有助于建立高性能、更可靠的分类模型。这种方法帮助我们优化了输入特征,提高了模型的分类准确性。
3.1.3 评价指标
以下指标是用于评估分类模型性能的常见度量指标,用于验证模型在处理数据时的表现。
- 准确率(Accuracy):
-
准确率是一个分类模型性能的基本度量标准。
-
它表示模型正确分类的样本数量与总样本数量之间的比率。
-
公式:准确率 = (TP+TN) / (TP+TN+FP+FN)
TP:真正例(模型正确预测为正类的样本数)
TN:真负例(模型正确预测为负类的样本数)
FP:假正例(模型错误预测为正类的样本数)
FN:假负例(模型错误预测为负类的样本数)
- 精确率(Precision):
- 精确率衡量的是模型在预测为正类的情况下,有多少样本实际为正类。
- 公式:精确率 = TP/(TP+FP)
- 召回率(Recall):
- 召回率衡量的是模型成功识别出的正类样本在总正类样本中的比例。
- 公式:召回率 = TP/(TP+FN)
- F1 分数(F1 Score):
- F1 分数是精确率和召回率的调和平均数,用于综合评估模型的性能。
- 公式:F1 分数 = 2PR/(P+R)
- AUC(Area Under the Curve):
- AUC 是 ROC 曲线下的面积,用于衡量模型在不同阈值下的性能。
- ROC 曲线是受试者工作特征曲线,它以 FPR(假正例率)为横轴,TPR(真正例率,即召回率)为纵轴,显示了不同阈值下的分类性能。
- AUC 值越接近 1,表示模型性能越好。
- 混淆矩阵(Confusion Matrix):
- 混淆矩阵是一个用于展示模型分类结果的矩阵。
- 它包括了真正例(TP)、真负例(TN)、假正例(FP)和假负例(FN)的数量。
- 通常以表格形式呈现,用于直观地展现模型的性能。
3.2 评估结果:在数据集 B 上的验证结果
基于十折交叉验证方法,我们使用了包括 XGBoost、RandomForest、AdaBoost、SVM、KNN、Logistic Regression 及其集成模型作为分类器进行预测,并运用上述多种度量指标对结果进行了较为全面的度量。XGBoost、RandomForest、AdaBoost 三个分类器效果较好,准确率接近 90%。而对于 Logistic 分类方法,效果在特征组 1 中较差,因为特征较多,导致预测结果接近全 1,这可能是由于特征较多导致的过拟合问题。在特征组 2 中效果较好,准确率达到 86%。此外 SVM 和 KNN 效果一般,它们对数据的敏感性较高,需要进行参数调整和特定数据情况下的优化才能达到较好的效果。最终,我们选择 XGBoost、RandomForest、AdaBoost 三种分类器,多次预测综合结果,总体预测准确率能达到 90%。通过组合多个模型的预测结果,可以提高整体性能,并降低过拟合的风险,减少单一分类器预测错误的数量。具体各个分类器的性能如下所述:
3.2.1 基于特征组 1 的分类预测性能评估
如第 2.1 节所述,特征组 1 包括 596 个不同的特征,用于 XGBoost,RandomForest,AdaBoost 等分类器。
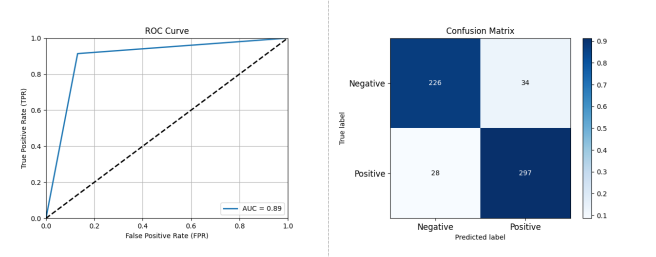
图 3-1 基于 XGBoost 的开源项目活跃度分类预测性能评估结果
如图 3-1 所示,采用 XGBoost 作为分类器,在包括 585 个开�源项目的数据集上进行十折交叉验证,其结果显示 XGBoost 的性能为准确率: 0.8940 精确率: 0.8973 召回率: 0.9138 F1 分数: 0.9055 AUC: 0.8915。结合混淆矩阵可以看出:通过 XGBoost 分类器,可以有效根据项目的 OSS Compass 指数对其未来是否会持续活跃进行准确预测。
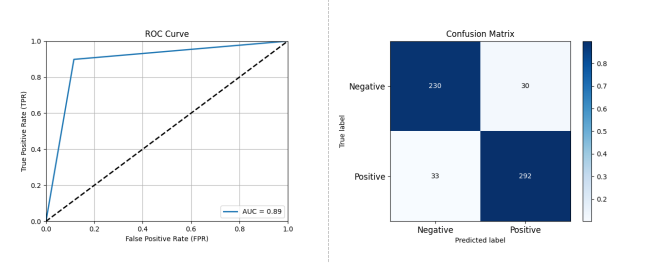
图 3-2 基于 Random Forest 的开源项目活跃度分类预测性能评估结果
如图 3-2 所示,采用 Random Forest 分类器,我们能够取得和 XGBoost 非常接近的分类预测性能。通过十折交叉验证验证,我们观察到 Random Forest 的分类预测性能为 准确率: 0.8923 精确率: 0.9068 召回率: 0.8985 F1 分数: 0.9026 AUC: 0.8915。
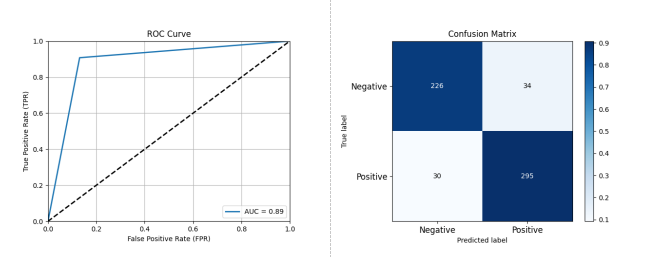
图 3-3 基于 AdaBoost + DecisionTree 的开源项目活跃度分类预测性能评估结果
如图 3-3 所示,AdaBoost + DecisionTree 分类器也展现出了较强的分类预测能力,其性能为准确率: 0.8906 精确率: 0.8967 召回率: 0.9077 F1 分数: 0.9021 AUC: 0.8885。
上述包括 XGBoost、Random Forest 和 AdaBoost 分类器的性能基本一致,都达到了接近 90%的分类准确率。目前图中所示的分类器性能的细微差别也可能是由于十折交叉验证过程中的随机因素导致的。
3.2.2 基于特征组 2 的分类预测性能评估
如第 2.1 节所述,特征组 2 包括 134 个特征,应用于包括 KNN、Logistic Regression、SVM 在内的分类器。相较采用特征组 1,这三个分类器采用特征组 2 能够取得更好的效果。
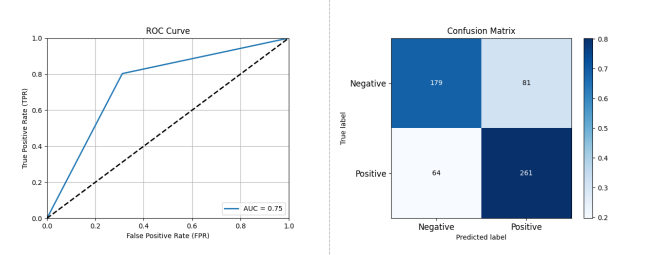
图 3-4 基于 KNN 的开源项目活跃度分类预测性能评估结果
如图 3-4 所示,采用 KNN 方法,能够有效实现对于开源项目未来活跃度的预测。相应的性能评估结果为准确率: 0.7521 精确率: 0.7632 召回率: 0.8031 F1 分数: 0.7826 AUC: 0.7457。
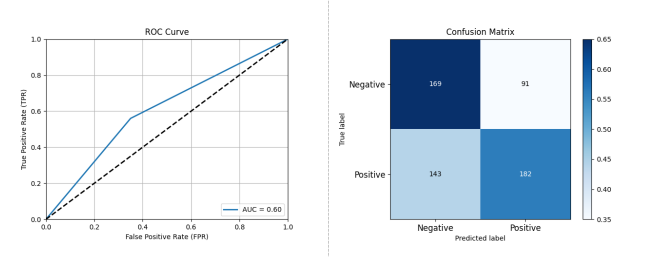
图 3-5 基于 SVM 的开源项目活跃度分类预测性能评估结果
如图 3-5 所示,基于 SVM 的方法其分类预测能力相对较弱,十折交叉验证的性能评估结果为准确率: 0.6291 精确率: 0.6812 召回率: 0.6246 F1 分数: 0.6517 AUC: 0.6296。
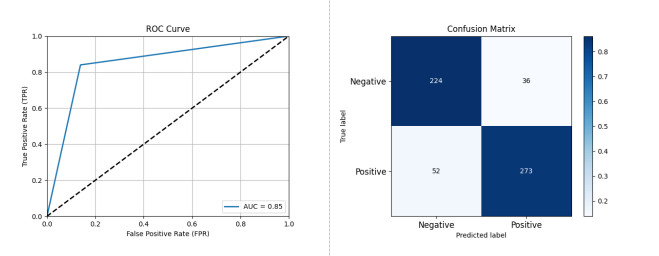
图 3-6 基于 Logistic Regression 的开源项目活跃度分类预测性能评估结果
如图 3-6 所示,在基于特征组 2 的分类预测方法中,Logistic Regression 方法展现出了优于 KNN 和 SVM 的性能,其准确率: 0.8496 精确率: 0.8835 召回率: 0.84 F1 分数: 0.8611 AUC: 0.8508。相较特征组 1,特征组 2 所对应的三个分类器的结果相对较弱,逻辑回归(Logistic Regression)方法展现出了接近特征组 1 分类器的性能。
3.2.3 集成学习和效果总览
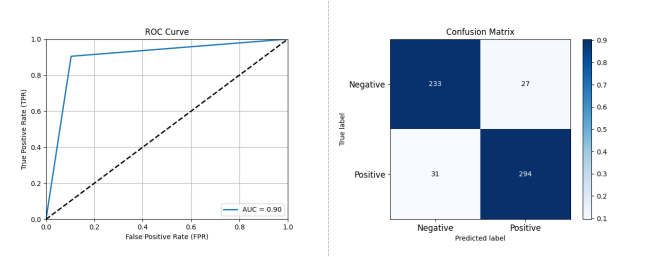
图 3-7 XGBoost、AdaBoost 和 RandomForest 三个分类器进行集成后的性能评估结果
基于上述实验结果,我们选择 2.1 节中基于特征组 1 的三个分类进行多数投票集成学习,并取得了相对最好的结果,实验结果显示,集成学习后的性能为准确率: 0.9009 精确率: 0.9159 召回率: 0.9046 F1 分数: 0.9102 AUC: 0.9004。
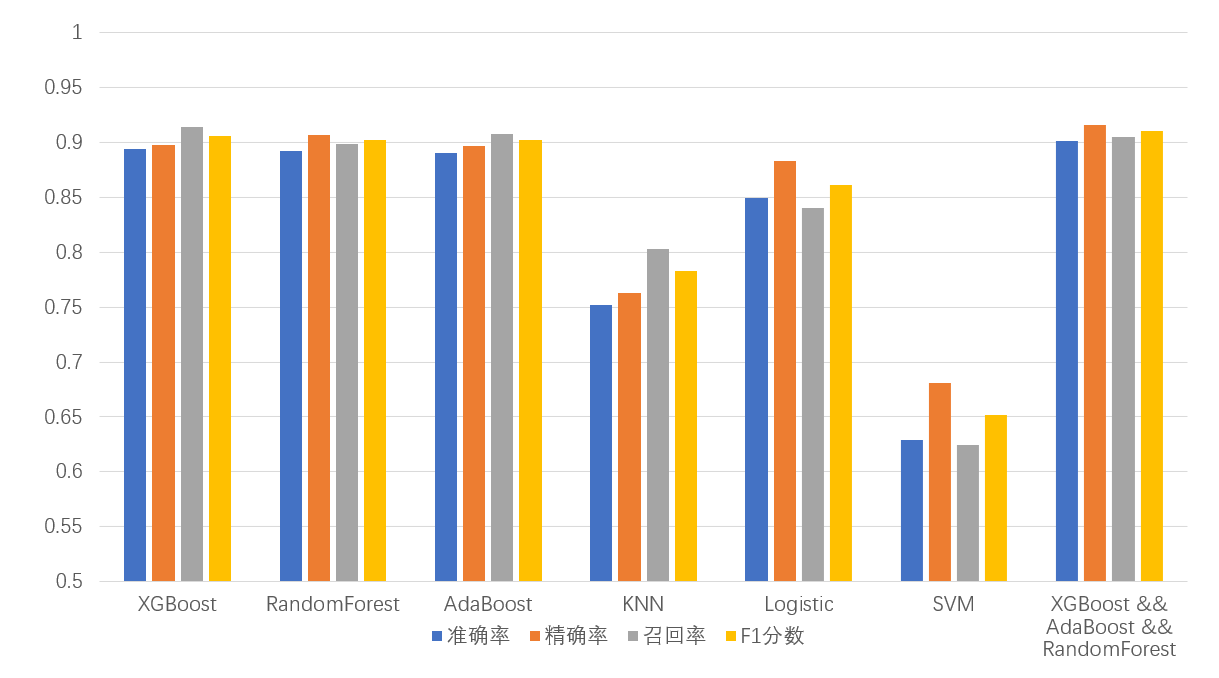
图 3-8 预测结果总览
最后,图 3-8 集中总结了在数据集 B 上的验证结果,列举了不同分类器包括准确率、精确率、召回率和 F1 分数在内的性能。实验结果显示,除了 KNN 和 SVM 以外,其余分类器都达到了 85%及以上的分类准确率。其中,综合多个分类器的集成学习方法展现出了最优的分类预测效果,有望在现实中开展应用。
3.3 评估结果:在数据集 A 上的泛化结果
我们利用 3.2 中获取模型的方法利用数据集 B 进行训练,包括 XGBoost、RandomForest、AdaBoost、SVM、KNN、Logistic Regression 及其集成模型。使用训练好的模型�对数据集 A 进行预测,验证模型在数据集 A 上的泛化能力。具体各个分类器的性能如下所述:
3.3.1 基于特征组 1 的分类预测性能评估
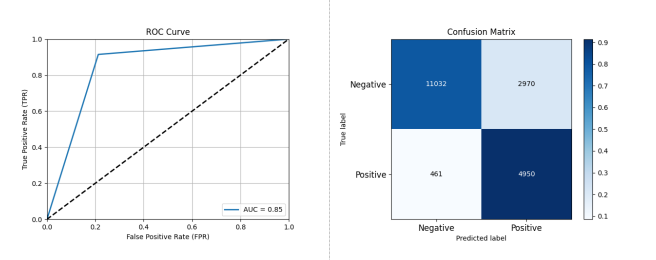
图 3-9 基于 XGBoost 的开源项目活跃度分类预测性能评估结果
如图 3-9 所示,采用 XGBoost 作为分类器,在数据集 A 上进行测试,其结果显示 XGBoost 的性能为准确率: 0.8233 精确率: 0.6250 召回率: 0.9148 F1 分数: 0.7426 AUC: 0.8513
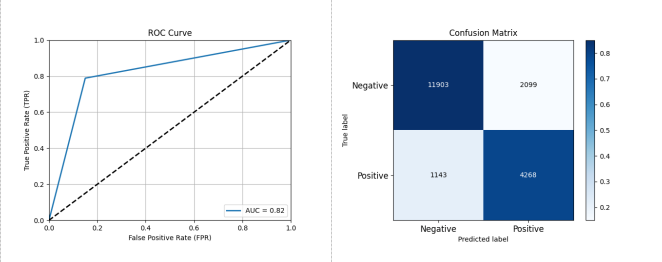
图 3-10 基于 RandomForest 的开源项目活跃度分类预测性能评估结果
如图 3-10 所示,采用 RandomForest 作为分类器,在数据集 A 上进行测试,其结果显示 RandomForest 的性能为准确率: 0.8330 精确率: 0.6703 召回率: 0.7888 F1 分数: 0.7247 AUC: 0.8194
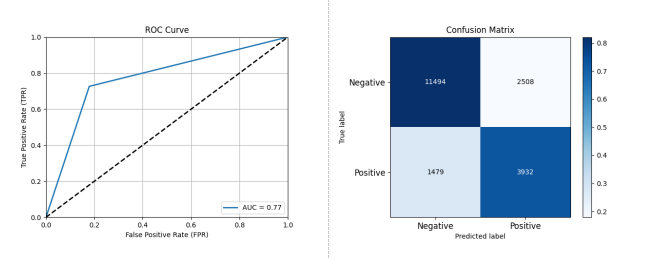
图 3-11 基于 AdaBoost 的开源项目活跃度分类预测性能评估结果
如图 3-11 所示,采用 AdaBoost 作为分类器,在数据集 A 上进行测试,其结果显示 AdaBoost 的性能为准确率: 0.8940 精确率: 0.7946 召回率: 0.6106 F1 分数: 0.6636 AUC: 0.7738
3.3.2 基于特征组 2 的分类预测性能评估
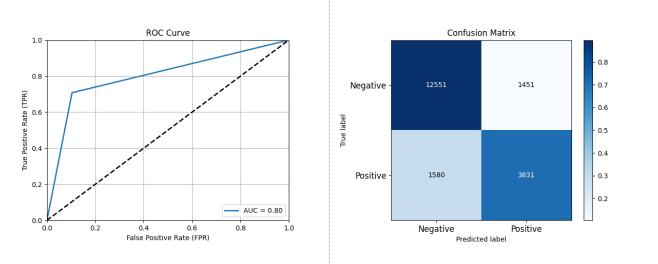
图 3-12 基于 KNN 的开源项目活跃度分类预测性能评估结果
如图 3-12 所示,采用 KNN 作为分类器,在数据集 A 上进行测试,其结果显示 KNN 的性能为准确率: 0.8439 精确率: 0.7253 召回率: 0.7080 F1 分数: 0.7165 AUC: 0.8022
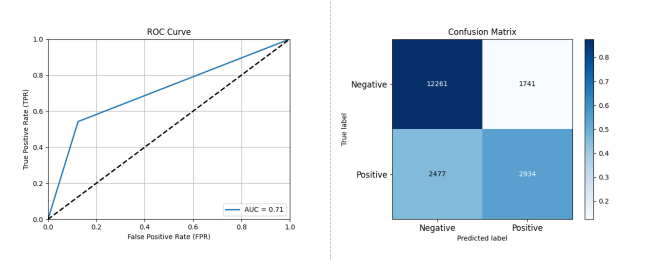
图 3-13 基于 SVM 的开源项目活跃度分类预测性能评估结果
如图 3-13 所示,采用 SVM 作为分类器,在数据集 A 上进行测试,其结果显示 SVM 的性能为准确率: 0.7827 精确率: 0.6276 召回率: 0.5422 F1 分数: 0.5818 AUC: 0.7089
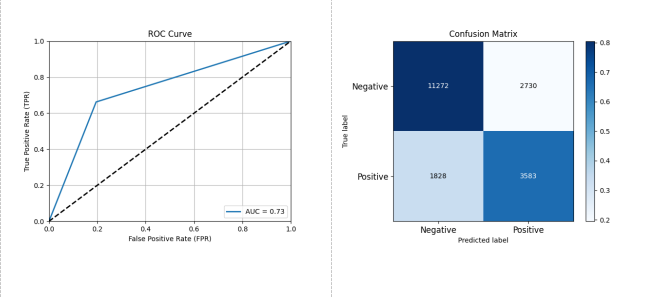
图 3-14 基于 Logistic Regression 的开源项目活跃度分类预测性能评估结果
如图 3-14 所示,采用 Logistic Regression 作为分类器,在数据集 A 上进行测试,其结果显示 Logistic Regression 的性能为准确率: 0.7652 精确率: 0.5676 召回率: 0.6622 F1 分数: 0.6112 AUC: 0.7336
3.3.3 集成学习和效果总览
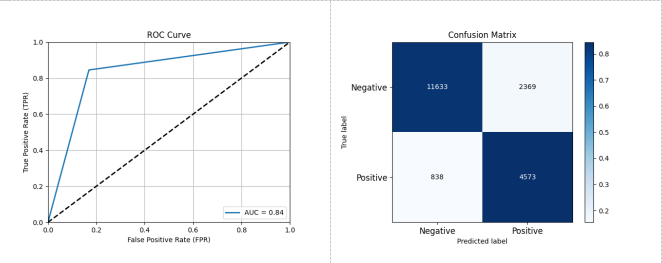
图 3-15 XGBoost、AdaBoost 和 RandomForest 三个分类器进行集成后的性能评估结果
如图 3-15 所示,采用 XGBoost、AdaBoost 和 RandomForest 作为集成分类器,在数据集 A 上进行测试,其结果显示 XGBoost、AdaBoost 和 RandomForest 集成分类器的性能为准确率: 0.8348 精确率: 0.6587 召回率: 0.8451 F1 分数: 0.7404 AUC: 0.8380
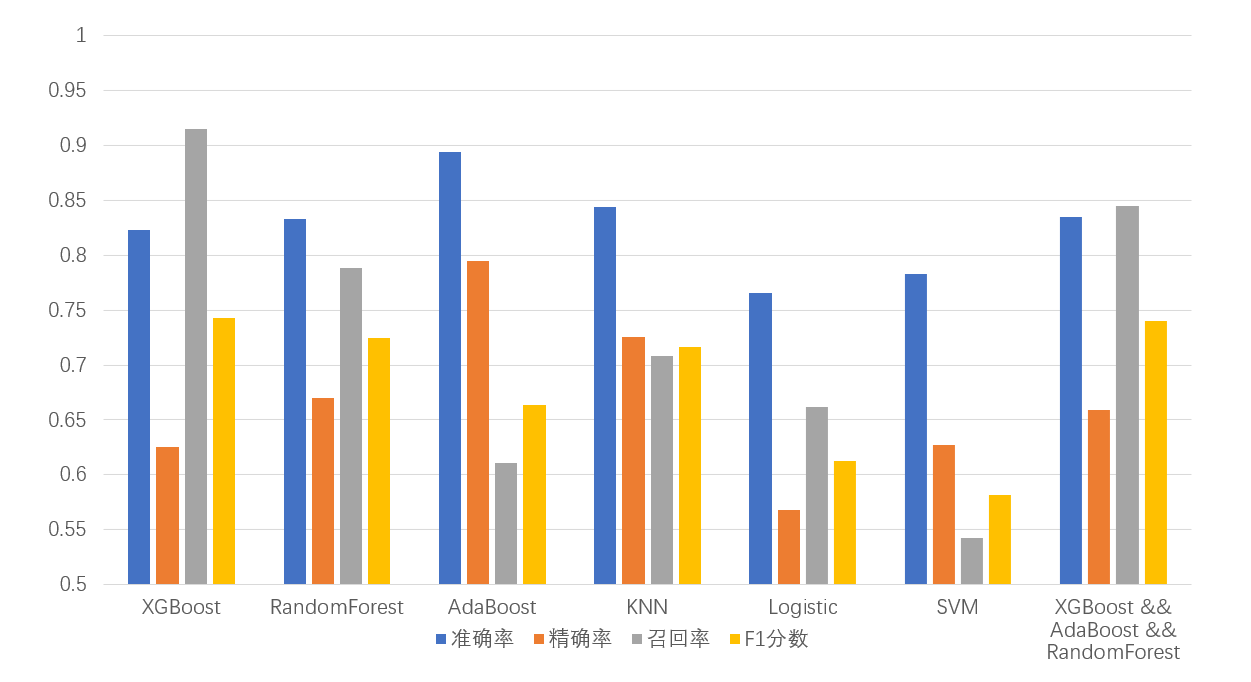
图 3-16 预测结果总览
最后,图 3-16 集中总结了在数据集 A 上的泛化结果,列举了不同分类器包括准确率、精确率、召回率和 F1 分数在内的性能。实验结果显示,KNN 和综合多个分类器的集成学习方法的分类预测效果较好,具有较强的泛化能力。推荐使用这两个模型来进行预测。
3.4 有效性威胁
首先是内部有效性威胁,从模型本身讲,尽管我们采用的是较为成熟的机器学习模型,但是由于数据集本身的数据量有限,模型的有效性也并未得到大规模验证,因此在实际场景中的效果还有待进一步的实验和证明。另一方面,本方法仅仅对 OSS-Compass 的模型指数进行了实验和预测,尽管从算法本身而言适用于一切时间序列预测场景,但是该方法能否��在其他场景下进一步推广还有待验证。
4 推荐的部署方案
基于上述实验结果,推荐使用 KNN 和综合多个分类器的集成学习方法作为学习器,在大规模数据集 A 上进行整体训练后,部署于实际平台中进行使用。
致谢
感谢开源社区的贡献者们和开源指南针平台提供的数据。感谢指导老师和同学们。本工作得到了南京大学大学生创新训练计划《基于度量指标的开源软件项目健康度预测技术研究》的支持。
附录 A 特征集合
A.1 特征组 1(包含 596 个特征,命名方式:指数名称__特征函数):
- commit_frequency_activity__minimum
- commit_frequency_codequality__minimum
- commit_frequency_without_bot_activity__minimum
- commit_frequency_without_bot_codequality__minimum
- pr_commit_count_codequality__minimum
- is_maintained_codequality__minimum
- lines_added_frequency_codequality__minimum
- LOC_frequency_codequality__minimum
- updated_since_activity__variance
- updated_since_activity__mean
- active_C2_contributor_count_codequality__minimum
- active_C2_contributor_count_activity__minimum
- is_maintained_codequality__sum_values
- lines_removed_frequency_codequality__minimum
- updated_since_activity__maximum
- code_quality_guarantee_codequality__minimum
- is_maintained_codequality__mean
- community_support_score_community__sum_values
- issue_open_time_avg_community__length
- pr_issue_linked_ratio_codequality__length
- commit_frequency_group_activity__length
- commit_frequency_without_bot_activity__length
- issue_first_reponse_mid_community__length
- active_C1_issue_create_contributor_activity__length
- community_support_score_community__length
- bug_issue_open_time_mid_community__length
- issue_open_time_mid_community__length
- pr_open_time_mid_community__length
- contribution_last_group_activity__length
- code_review_ratio_codequality__length
- contributor_count_bot_codequality__length
- bug_issue_open_time_avg_community__length
- lines_removed_frequency_codequality__length
- pr_first_response_time_avg_community__length
- commit_frequency_org_group_activity__length
- commit_frequency_without_bot_codequality__length
- commit_frequency_bot_activity__length
- code_review_count_community__length
- activity_score_activity__length
- code_merge_ratio_codequality__length
- contributor_count_without_bot_codequality__length
- code_review_count_activity__length
- commit_frequency_percentage_group_activity__length
- org_count_activity__length
- closed_issues_count_activity__length
- pr_count_codequality__length
- updated_since_activity__length
- contributor_count_without_bot_activity__length
- pr_first_response_time_mid_community__length
- org_count_group_activity__length
- comment_frequency_community__length
- recent_releases_count_activity__length
- active_C1_pr_create_contributor_codequality__length
- contributor_count_activity__length
- active_C2_contributor_count_activity__length
- updated_issues_count_activity__length
- updated_issues_count_community__length
- is_maintained_codequality__length
- active_C1_pr_comments_contributor_activity__length
- comment_frequency_activity__length
- active_C1_pr_create_contributor_activity__length
- code_quality_guarantee_codequality__length
- contributor_count_codequality__length
- commit_frequency_inside_codequality__length
- contributor_count_group_activity__length
- contributor_count_without_bot_group_activity__length
- contributor_count_bot_group_activity__length
- commit_frequency_codequality__length
- git_pr_linked_ratio_codequality__length
- commit_frequency_inside_without_bot_codequality__length
- commit_frequency_inside_bot_codequality__length
- commit_frequency_bot_codequality__length
- active_C1_pr_comments_contributor_codequality__length
- commit_frequency_bot_group_activity__length
- contributor_count_bot_activity__length
- pr_commit_count_codequality__length
- lines_added_frequency_codequality__length
- pr_open_time_avg_community__length
- commit_frequency_without_bot_group_activity__length
- contributor_org_count_group_activity__length
- issue_first_reponse_avg_community__length
- LOC_frequency_codequality__length
- active_C2_contributor_count_codequality__length
- commit_frequency_activity__length
- organizations_activity_group_activity__length
- active_C1_issue_comments_contributor_activity__length
- closed_prs_count_community__length
- pr_merged_count_codequality__length
- pr_commit_linked_count_codequality__length
- commit_frequency_org_percentage_group_activity__length
- community_support_score_community__minimum
- updated_since_activity__mean_abs_change
- activity_score_activity__sum_values
- closed_prs_count_community__minimum
- code_quality_guarantee_codequality__sum_values
- commit_frequency_org_percentage_group_activity__maximum
- activity_score_activity__minimum
- pr_merged_count_codequality__minimum
- commit_frequency_codequality__sum_values
- commit_frequency_activity__sum_values
- contributor_count_codequality__minimum
- commit_frequency_without_bot_codequality__sum_values
- commit_frequency_without_bot_activity__sum_values
- contributor_count_without_bot_codequality__minimum
- community_support_score_community__mean
- pr_commit_count_codequality__sum_values
- active_C2_contributor_count_codequality__sum_values
- active_C2_contributor_count_activity__sum_values
- closed_prs_count_community__sum_values
- pr_count_codequality__minimum
- commit_frequency_org_percentage_group_activity__mean
- commit_frequency_codequality__mean
- commit_frequency_activity__mean
- commit_frequency_without_bot_codequality__mean
- commit_frequency_without_bot_activity__mean
- activity_score_activity__mean
- contributor_org_count_group_activity__sum_values
- updated_since_activity__sum_values
- pr_count_codequality__sum_values
- pr_commit_count_codequality__mean
- commit_frequency_org_group_activity__absolute_sum_of_changes
- commit_frequency_codequality__absolute_sum_of_changes
- commit_frequency_activity__absolute_sum_of_changes
- commit_frequency_without_bot_activity__absolute_sum_of_changes
- commit_frequency_without_bot_codequality__absolute_sum_of_changes
- commit_frequency_org_group_activity__sum_values
- closed_prs_count_community__absolute_sum_of_changes
- pr_count_codequality__absolute_sum_of_changes
- closed_prs_count_community__mean
- code_quality_guarantee_codequality__mean
- active_C2_contributor_count_codequality__mean
- active_C2_contributor_count_activity__mean
- pr_merged_count_codequality__sum_values
- pr_commit_count_codequality__absolute_sum_of_changes
- pr_merged_count_codequality__absolute_sum_of_changes
- commit_frequency_org_group_activity__mean_abs_change
- pr_open_time_avg_community__variance
- commit_frequency_activity__mean_abs_change
- is_maintained_codequality__maximum
- commit_frequency_codequality__mean_abs_change
- commit_frequency_org_percentage_group_activity__last_location_of_maximum
- active_C1_pr_comments_contributor_activity__sum_values
- active_C1_pr_comments_contributor_codequality__sum_values
- commit_frequency_without_bot_activity__mean_abs_change
- commit_frequency_without_bot_codequality__mean_abs_change
- pr_open_time_mid_community__mean_abs_change
- commit_frequency_org_group_activity__mean
- pr_open_time_mid_community__variance
- pr_count_codequality__mean
- pr_open_time_avg_community__mean_abs_change
- active_C1_pr_comments_contributor_activity__minimum
- active_C1_pr_comments_contributor_codequality__minimum
- active_C1_pr_create_contributor_activity__minimum
- active_C1_pr_create_contributor_codequality__minimum
- pr_merged_count_codequality__mean
- contributor_count_codequality__sum_values
- contributor_count_without_bot_codequality__sum_values
- closed_prs_count_community__mean_abs_change
- contributor_org_count_group_activity__absolute_sum_of_changes
- pr_commit_count_codequality__mean_abs_change
- pr_merged_count_codequality__mean_abs_change
- pr_count_codequality__mean_abs_change
- code_review_count_community__sum_values
- active_C2_contributor_count_codequality__absolute_sum_of_changes
- active_C2_contributor_count_activity__absolute_sum_of_changes
- pr_count_codequality__maximum
- active_C1_pr_comments_contributor_codequality__mean
- active_C1_pr_comments_contributor_activity__mean
- commit_frequency_percentage_group_activity__mean
- closed_prs_count_community__maximum
- commit_frequency_codequality__maximum
- commit_frequency_activity__maximum
- pr_open_time_avg_community__maximum
- pr_open_time_mid_community__maximum
- commit_frequency_without_bot_activity__maximum
- commit_frequency_without_bot_codequality__maximum
- pr_merged_count_codequality__maximum
- contributor_org_count_group_activity__mean_abs_change
- active_C1_pr_create_contributor_codequality__sum_values
- active_C1_pr_create_contributor_activity__sum_values
- active_C1_pr_comments_contributor_codequality__absolute_sum_of_changes
- active_C1_pr_comments_contributor_activity__absolute_sum_of_changes
- pr_commit_count_codequality__maximum
- community_support_score_community__maximum
- closed_issues_count_activity__minimum
- pr_first_response_time_mid_community__last_location_of_minimum
- code_review_count_community__mean
- pr_open_time_mid_community__mean
- commit_frequency_org_group_activity__variance
- active_C1_pr_comments_contributor_codequality__maximum
- active_C1_pr_comments_contributor_activity__maximum
- contributor_org_count_group_activity__mean
- code_review_count_community__last_location_of_minimum
- active_C2_contributor_count_activity__maximum
- active_C2_contributor_count_codequality__maximum
- contributor_count_codequality__mean
- contributor_count_without_bot_codequality__mean
- active_C2_contributor_count_codequality__mean_abs_change
- active_C2_contributor_count_activity__mean_abs_change
- commit_frequency_org_percentage_group_activity__skewness
- code_review_ratio_codequality__last_location_of_minimum
- commit_frequency_org_group_activity__maximum
- code_review_count_activity__last_location_of_minimum
- pr_merged_count_codequality__variance
- code_merge_ratio_codequality__minimum
- activity_score_activity__skewness
- pr_count_codequality__variance
- activity_score_activity__maximum
- updated_since_activity__kurtosis
- contributor_org_count_group_activity__variance
- contributor_count_codequality__absolute_sum_of_changes
- contributor_count_without_bot_codequality__absolute_sum_of_changes
- code_review_ratio_codequality__minimum
- active_C2_contributor_count_codequality__last_location_of_minimum
- active_C2_contributor_count_activity__last_location_of_minimum
- active_C1_pr_comments_contributor_activity__mean_abs_change
- active_C1_pr_comments_contributor_codequality__mean_abs_change
- active_C1_pr_create_contributor_activity__mean
- active_C1_pr_create_contributor_codequality__mean
- code_quality_guarantee_codequality__maximum
- pr_issue_linked_ratio_codequalitylarge_standard_deviationr_0.05
- active_C1_pr_create_contributor_codequality__absolute_sum_of_changes
- active_C1_pr_create_contributor_activity__absolute_sum_of_changes
- contributor_org_count_group_activity__maximum
- pr_first_response_time_mid_community__minimum
- pr_first_response_time_avg_community__minimum
- closed_prs_count_community__variance
- pr_issue_linked_ratio_codequalitylarge_standard_deviationr_0.1
- code_review_count_activity__minimum
- commit_frequency_activity__last_location_of_minimum
- commit_frequency_codequality__last_location_of_minimum
- commit_frequency_without_bot_activity__last_location_of_minimum
- commit_frequency_without_bot_codequality__last_location_of_minimum
- code_review_count_community__minimum
- contributor_count_codequality__maximum
- contributor_count_without_bot_codequality__maximum
- pr_open_time_mid_community__absolute_sum_of_changes
- lines_removed_frequency_codequality__sum_values
- commit_frequency_codequality__variance
- commit_frequency_activity__variance
- commit_frequency_percentage_group_activity__last_location_of_maximum
- commit_frequency_without_bot_codequality__variance
- LOC_frequency_codequality__sum_values
- commit_frequency_without_bot_activity__variance
- contributor_count_activity__minimum
- contributor_count_without_bot_activity__minimum
- lines_added_frequency_codequality__sum_values
- code_review_count_activity__sum_values
- lines_removed_frequency_codequality__absolute_sum_of_changes
- code_review_count_community__absolute_sum_of_changes
- bug_issue_open_time_mid_community__last_location_of_minimum
- pr_first_response_time_avg_community__last_location_of_minimum
- updated_since_activity__mean_change
- closed_issues_count_activity__sum_values
- pr_issue_linked_ratio_codequality__sum_values
- pr_commit_linked_count_codequality__absolute_sum_of_changes
- active_C1_pr_comments_contributor_activity__variance
- active_C1_pr_comments_contributor_codequality__variance
- LOC_frequency_codequality__absolute_sum_of_changes
- lines_added_frequency_codequality__absolute_sum_of_changes
- pr_commit_count_codequality__variance
- updated_issues_count_activity__sum_values
- updated_issues_count_community__sum_values
- pr_commit_linked_count_codequality__sum_values
- bug_issue_open_time_avg_community__last_location_of_minimum
- pr_issue_linked_ratio_codequality__mean
- active_C1_issue_create_contributor_activity__minimum
- recent_releases_count_activity__minimum
- active_C1_pr_create_contributor_activity__maximum
- active_C1_pr_create_contributor_codequality__maximum
- lines_removed_frequency_codequality__mean
- updated_issues_count_activity__minimum
- updated_issues_count_community__minimum
- LOC_frequency_codequality__mean
- lines_added_frequency_codequality__mean
- code_review_ratio_codequality__sum_values
- lines_removed_frequency_codequality__mean_abs_change
- updated_since_activity__last_location_of_minimum
- pr_issue_linked_ratio_codequality__absolute_sum_of_changes
- code_review_count_community__maximum
- pr_commit_linked_count_codequality__maximum
- pr_issue_linked_ratio_codequality__mean_abs_change
- code_review_count_activity__mean
- pr_commit_linked_count_codequality__mean_abs_change
- LOC_frequency_codequality__mean_abs_change
- updated_issues_count_community__absolute_sum_of_changes
- updated_issues_count_activity__absolute_sum_of_changes
- contributor_count_without_bot_activity__sum_values
- contributor_count_activity__sum_values
- lines_added_frequency_codequality__mean_abs_change
- pr_open_time_avg_community__absolute_sum_of_changes
- active_C1_pr_comments_contributor_codequality__last_location_of_minimum
- active_C1_pr_comments_contributor_activity__last_location_of_minimum
- pr_issue_linked_ratio_codequality__first_location_of_maximum
- pr_issue_linked_ratio_codequality__last_location_of_maximum
- comment_frequency_activity__minimum
- comment_frequency_community__minimum
- pr_commit_count_codequality__last_location_of_minimum
- active_C1_issue_comments_contributor_activity__minimum
- pr_commit_linked_count_codequality__mean
- pr_open_time_avg_community__mean
- updated_since_activity__skewness
- contributor_count_codequality__mean_abs_change
- contributor_count_without_bot_codequality__mean_abs_change
- pr_open_time_mid_community__sum_values
- active_C1_issue_create_contributor_activity__sum_values
- pr_issue_linked_ratio_codequality__last_location_of_minimum
- lines_removed_frequency_codequality__maximum
- closed_issues_count_activity__absolute_sum_of_changes
- code_review_count_community__mean_abs_change
- pr_issue_linked_ratio_codequality__variance
- commit_frequency_percentage_group_activity__skewness
- active_C1_pr_create_contributor_codequality__mean_abs_change
- active_C1_pr_create_contributor_activity__mean_abs_change
- updated_since_activity__absolute_sum_of_changes
- pr_commit_linked_count_codequality__variance
- pr_issue_linked_ratio_codequality__maximum
- closed_issues_count_activity__mean
- LOC_frequency_codequality__maximum
- pr_first_response_time_avg_community__first_location_of_minimum
- issue_open_time_avg_community__variance
- active_C1_issue_create_contributor_activity__absolute_sum_of_changes
- code_review_count_activity__first_location_of_minimum
- code_review_count_community__first_location_of_minimum
- active_C2_contributor_count_activity__variance
- active_C2_contributor_count_codequality__variance
- code_quality_guarantee_codequality__variance
- pr_issue_linked_ratio_codequality__first_location_of_minimum
- lines_added_frequency_codequality__maximum
- lines_removed_frequency_codequality__variance
- code_merge_ratio_codequality__last_location_of_minimum
- active_C1_issue_comments_contributor_activity__sum_values
- commit_frequency_percentage_group_activity__absolute_sum_of_changes
- issue_open_time_mid_community__variance
- code_review_ratio_codequality__first_location_of_minimum
- bug_issue_open_time_avg_community__minimum
- updated_issues_count_activity__mean
- updated_issues_count_community__mean
- code_review_ratio_codequality__mean
- updated_since_activity__minimum
- LOC_frequency_codequality__variance
- issue_open_time_avg_community__mean_abs_change
- activity_score_activity__mean_change
- bug_issue_open_time_mid_community__minimum
- issue_open_time_avg_community__maximum
- is_maintained_codequalitylarge_standard_deviationr_0.1
- contributor_count_without_bot_activity__absolute_sum_of_changes
- updated_issues_count_activity__last_location_of_minimum
- updated_issues_count_community__last_location_of_minimum
- contributor_count_activity__absolute_sum_of_changes
- issue_first_reponse_mid_community__mean_abs_change
- lines_added_frequency_codequality__variance
- code_quality_guarantee_codequality__mean_abs_change
- issue_open_time_mid_community__mean_abs_change
- is_maintained_codequalitylarge_standard_deviationr_0.05
- issue_open_time_mid_community__maximum
- pr_commit_linked_count_codequality__minimum
- recent_releases_count_activity__sum_values
- pr_first_response_time_mid_community__first_location_of_minimum
- issue_first_reponse_mid_community__variance
- community_support_score_community__mean_abs_change
- is_maintained_codequality__last_location_of_maximum
- pr_merged_count_codequality__last_location_of_minimum
- updated_issues_count_activity__maximum
- updated_issues_count_community__maximum
- recent_releases_count_activity__absolute_sum_of_changes
- issue_first_reponse_avg_community__mean_abs_change
- contributor_count_activity__mean
- contributor_count_without_bot_activity__mean
- active_C1_issue_comments_contributor_activity__absolute_sum_of_changes
- code_review_count_activity__absolute_sum_of_changes
- active_C1_issue_create_contributor_activity__mean
- issue_first_reponse_mid_community__maximum
- closed_issues_count_activity__maximum
- code_review_count_activitylarge_standard_deviationr_0.05
- code_review_count_activitylarge_standard_deviationr_0.1
- code_review_count_communitylarge_standard_deviationr_0.05
- code_review_count_communitylarge_standard_deviationr_0.1
- recent_releases_count_activity__mean
- closed_issues_count_activity__mean_abs_change
- contributor_count_codequality__variance
- contributor_count_without_bot_codequality__variance
- code_review_ratio_codequalitylarge_standard_deviationr_0.05
- code_review_ratio_codequalitylarge_standard_deviationr_0.1
- pr_first_response_time_avg_communitylarge_standard_deviationr_0.1
- commit_frequency_org_percentage_group_activity__absolute_sum_of_changes
- pr_first_response_time_mid_communitylarge_standard_deviationr_0.05
- pr_first_response_time_avg_communitylarge_standard_deviationr_0.05
- issue_first_reponse_avg_community__last_location_of_maximum
- pr_first_response_time_mid_communitylarge_standard_deviationr_0.1
- code_merge_ratio_codequality__first_location_of_maximum
- community_support_score_community__variance
- code_merge_ratio_codequality__variance
- contributor_count_without_bot_group_activity__absolute_sum_of_changes
- recent_releases_count_activity__maximum
- issue_first_reponse_mid_community__mean
- commit_frequency_org_percentage_group_activity__sum_values
- contributor_count_group_activity__absolute_sum_of_changes
- updated_issues_count_activity__mean_abs_change
- updated_issues_count_community__mean_abs_change
- active_C1_pr_create_contributor_activity__variance
- active_C1_pr_create_contributor_codequality__variance
- closed_prs_count_community__last_location_of_minimum
- org_count_group_activity__sum_values
- org_count_activity__sum_values
- contributor_count_group_activity__sum_values
- contributor_count_without_bot_group_activity__sum_values
- organizations_activity_group_activity__sum_values
- comment_frequency_community__sum_values
- comment_frequency_activity__sum_values
- contributor_count_group_activity__maximum
- contributor_count_without_bot_group_activity__maximum
- recent_releases_count_activity__mean_abs_change
- contribution_last_group_activity__sum_values
- org_count_group_activity__maximum
- org_count_activity__maximum
- active_C1_issue_create_contributor_activity__maximum
- pr_issue_linked_ratio_codequality__skewness
- community_support_score_community__mean_change
- activity_score_activity__absolute_sum_of_changes
- code_review_count_community__first_location_of_maximum
- organizations_activity_group_activity__absolute_sum_of_changes
- organizations_activity_group_activity__maximum
- active_C1_issue_comments_contributor_activity__mean
- git_pr_linked_ratio_codequality__last_location_of_maximum
- contributor_count_without_bot_activity__maximum
- contributor_count_activity__maximum
- issue_first_reponse_avg_community__variance
- bug_issue_open_time_avg_community__sum_values
- contribution_last_group_activity__absolute_sum_of_changes
- org_count_group_activity__absolute_sum_of_changes
- commit_frequency_org_percentage_group_activity__first_location_of_maximum
- org_count_activity__absolute_sum_of_changes
- contribution_last_group_activity__maximum
- contributor_count_without_bot_group_activity__mean_abs_change
- org_count_group_activity__mean
- org_count_activity__mean
- contributor_count_group_activity__mean
- code_review_count_activity__maximum
- contributor_count_without_bot_group_activity__mean
- contributor_count_group_activity__mean_abs_change
- issue_first_reponse_mid_community__absolute_sum_of_changes
- commit_frequency_group_activity__absolute_sum_of_changes
- organizations_activity_group_activity__mean
- commit_frequency_without_bot_group_activity__absolute_sum_of_changes
- commit_frequency_group_activity__sum_values
- commit_frequency_without_bot_group_activity__sum_values
- lines_removed_frequency_codequality__last_location_of_minimum
- active_C1_pr_comments_contributor_codequality__first_location_of_minimum
- active_C1_pr_comments_contributor_activity__first_location_of_minimum
- contributor_count_group_activity__variance
- contributor_count_without_bot_group_activity__variance
- contribution_last_group_activity__mean
- pr_open_time_avg_community__minimum
- lines_added_frequency_codequality__last_location_of_minimum
- issue_first_reponse_avg_community__maximum
- code_review_count_activity__mean_abs_change
- commit_frequency_group_activity__maximum
- commit_frequency_without_bot_group_activity__maximum
- active_C1_issue_create_contributor_activity__mean_abs_change
- issue_first_reponse_avg_community__first_location_of_minimum
- updated_issues_count_activity__mean_change
- updated_issues_count_community__mean_change
- commit_frequency_group_activity__mean
- commit_frequency_group_activity__mean_abs_change
- commit_frequency_without_bot_group_activity__mean
- commit_frequency_without_bot_group_activity__mean_abs_change
- code_merge_ratio_codequality__last_location_of_maximum
- pr_commit_linked_count_codequality__last_location_of_minimum
- updated_issues_count_activity__variance
- updated_issues_count_community__variance
- commit_frequency_percentage_group_activity__mean_abs_change
- contribution_last_group_activity__mean_abs_change
- commit_frequency_without_bot_group_activity__last_location_of_minimum
- organizations_activity_group_activity__last_location_of_minimum
- closed_issues_count_activity__last_location_of_minimum
- commit_frequency_group_activity__last_location_of_minimum
- commit_frequency_group_activity__variance
- commit_frequency_without_bot_group_activity__variance
- LOC_frequency_codequality__last_location_of_minimum
- pr_first_response_time_mid_community__first_location_of_maximum
- active_C1_issue_comments_contributor_activity__maximum
- code_review_count_community__variance
- issue_open_time_mid_community__mean
- org_count_group_activity__mean_abs_change
- org_count_activity__mean_abs_change
- organizations_activity_group_activity__mean_abs_change
- contribution_last_group_activity__variance
- recent_releases_count_activity__last_location_of_minimum
- contributor_count_codequality__last_location_of_minimum
- is_maintained_codequality__variance
- pr_first_response_time_avg_community__last_location_of_maximum
- contributor_count_without_bot_codequality__last_location_of_minimum
- org_count_group_activity__variance
- org_count_activity__variance
- contributor_count_group_activity__last_location_of_minimum
- commit_frequency_without_bot_group_activitylarge_standard_deviationr_0.1
- commit_frequency_group_activitylarge_standard_deviationr_0.1
- pr_count_codequality__last_location_of_minimum
- commit_frequency_group_activitylarge_standard_deviationr_0.05
- commit_frequency_without_bot_group_activitylarge_standard_deviationr_0.05
- contributor_count_without_bot_group_activitylarge_standard_deviationr_0.1
- contributor_count_group_activitylarge_standard_deviationr_0.1
- git_pr_linked_ratio_codequality__maximum
- contributor_count_without_bot_group_activity__last_location_of_minimum
- issue_first_reponse_mid_community__sum_values
- contribution_last_group_activity__minimum
- commit_frequency_org_percentage_group_activity__minimum
- organizations_activity_group_activitylarge_standard_deviationr_0.1
- contribution_last_group_activity__last_location_of_minimum
- recent_releases_count_activity__variance
- commit_frequency_without_bot_group_activity__first_location_of_minimum
- contributor_count_group_activitylarge_standard_deviationr_0.05
- contributor_count_without_bot_group_activitylarge_standard_deviationr_0.05
- bug_issue_open_time_avg_community__mean
- is_maintained_codequality__mean_abs_change
- contribution_last_group_activitylarge_standard_deviationr_0.1
- contribution_last_group_activitylarge_standard_deviationr_0.05
- organizations_activity_group_activitylarge_standard_deviationr_0.05
- commit_frequency_group_activity__first_location_of_minimum
- code_merge_ratio_codequality__maximum
- contributor_org_count_group_activitylarge_standard_deviationr_0.05
- organizations_activity_group_activity__minimum
- contributor_count_group_activity__minimum
- closed_issues_count_activity__variance
- org_count_activity__minimum
- org_count_group_activity__minimum
- commit_frequency_group_activity__minimum
- commit_frequency_percentage_group_activity__first_location_of_maximum
- git_pr_linked_ratio_codequality__minimum
- contributor_org_count_group_activitylarge_standard_deviationr_0.1
- issue_first_reponse_avg_community__mean
- organizations_activity_group_activity__first_location_of_minimum
- is_maintained_codequality__skewness
- contributor_count_without_bot_activity__mean_abs_change
- contributor_count_bot_activity__sum_values
- org_count_activitylarge_standard_deviationr_0.1
- org_count_group_activitylarge_standard_deviationr_0.1
- contributor_count_activity__mean_abs_change
- pr_merged_count_codequality__first_location_of_maximum
- community_support_score_community__last_location_of_minimum
- git_pr_linked_ratio_codequality__variance
- issue_first_reponse_avg_community__absolute_sum_of_changes
- contribution_last_group_activity__first_location_of_minimum
- bug_issue_open_time_mid_community__sum_values
- comment_frequency_activity__variance
- comment_frequency_community__variance
- code_review_count_activity__variance
- commit_frequency_without_bot_group_activity__last_location_of_maximum
- commit_frequency_group_activity__last_location_of_maximum
- contributor_count_without_bot_group_activity__minimum
- contributor_org_count_group_activity__last_location_of_minimum
- bug_issue_open_time_avg_community__first_location_of_minimum
- pr_first_response_time_avg_community__sum_values
- org_count_activitylarge_standard_deviationr_0.05
- org_count_group_activitylarge_standard_deviationr_0.05
- commit_frequency_without_bot_group_activity__minimum
- commit_frequency_percentage_group_activity__sum_values
- commit_frequency_percentage_group_activity__minimum
- contributor_count_without_bot_group_activity__first_location_of_minimum
- code_review_ratio_codequality__last_location_of_maximum
- org_count_group_activity__last_location_of_minimum
- org_count_activity__last_location_of_minimum
- code_review_ratio_codequality__first_location_of_maximum
- contributor_count_group_activity__first_location_of_minimum
- contributor_count_bot_activity__mean
- commit_frequency_org_group_activity__first_location_of_maximum
- active_C1_issue_comments_contributor_activity__mean_abs_change
- recent_releases_count_activity__first_location_of_maximum
- code_merge_ratio_codequality__sum_values
- contributor_count_without_bot_group_activity__first_location_of_maximum
- contributor_count_group_activity__first_location_of_maximum
- active_C1_pr_comments_contributor_activitylarge_standard_deviationr_0.05
- active_C1_pr_comments_contributor_codequalitylarge_standard_deviationr_0.05
- active_C1_pr_comments_contributor_activitylarge_standard_deviationr_0.1
- active_C1_pr_comments_contributor_codequalitylarge_standard_deviationr_0.1
- commit_frequency_percentage_group_activitylarge_standard_deviationr_0.05
- active_C1_pr_create_contributor_codequality__last_location_of_minimum
- active_C1_pr_create_contributor_activity__last_location_of_minimum
- bug_issue_open_time_mid_communitylarge_standard_deviationr_0.05
- bug_issue_open_time_mid_communitylarge_standard_deviationr_0.1
- bug_issue_open_time_avg_communitylarge_standard_deviationr_0.05
- bug_issue_open_time_avg_communitylarge_standard_deviationr_0.1
- activity_score_activity__last_location_of_minimum
- contributor_count_bot_activity__maximum
- bug_issue_open_time_mid_community__first_location_of_maximum
- contributor_org_count_group_activity__first_location_of_maximum
- organizations_activity_group_activity__first_location_of_maximum
- commit_frequency_without_bot_group_activity__first_location_of_maximum
- code_review_count_activity__first_location_of_maximum
- commit_frequency_group_activity__first_location_of_maximum
- bug_issue_open_time_mid_community__first_location_of_minimum
- commit_frequency_org_percentage_group_activitylarge_standard_deviationr_0.1
- commit_frequency_org_percentage_group_activitylarge_standard_deviationr_0.05
- pr_open_time_mid_community__minimum
- organizations_activity_group_activity**last_location_of_maximum
A.2 特征组 2 (包含 134 个特征,命名方式:指数名称**特征函数)
- commit_frequency_activity__minimum
- commit_frequency_codequality__minimum
- commit_frequency_without_bot_activity__minimum
- commit_frequency_without_bot_codequality__minimum
- pr_commit_count_codequality__minimum
- is_maintained_codequality__minimum
- lines_added_frequency_codequality__minimum
- LOC_frequency_codequality__minimum
- updated_since_activity__variance
- updated_since_activity__mean
- active_C2_contributor_count_codequality__minimum
- active_C2_contributor_count_activity__minimum
- is_maintained_codequality__sum_values
- lines_removed_frequency_codequality__minimum
- updated_since_activity__maximum
- code_quality_guarantee_codequality__minimum
- is_maintained_codequality__mean
- community_support_score_community__sum_values
- issue_open_time_avg_community__length
- pr_issue_linked_ratio_codequality__length
- commit_frequency_group_activity__length
- commit_frequency_without_bot_activity__length
- issue_first_reponse_mid_community__length
- active_C1_issue_create_contributor_activity__length
- community_support_score_community__length
- bug_issue_open_time_mid_community__length
- issue_open_time_mid_community__length
- pr_open_time_mid_community__length
- contribution_last_group_activity__length
- code_review_ratio_codequality__length
- contributor_count_bot_codequality__length
- bug_issue_open_time_avg_community__length
- lines_removed_frequency_codequality__length
- pr_first_response_time_avg_community__length
- commit_frequency_org_group_activity__length
- commit_frequency_without_bot_codequality__length
- commit_frequency_bot_activity__length
- code_review_count_community__length
- activity_score_activity__length
- code_merge_ratio_codequality__length
- contributor_count_without_bot_codequality__length
- code_review_count_activity__length
- commit_frequency_percentage_group_activity__length
- org_count_activity__length
- closed_issues_count_activity__length
- pr_count_codequality__length
- updated_since_activity__length
- contributor_count_without_bot_activity__length
- pr_first_response_time_mid_community__length
- org_count_group_activity__length
- comment_frequency_community__length
- recent_releases_count_activity__length
- active_C1_pr_create_contributor_codequality__length
- contributor_count_activity__length
- active_C2_contributor_count_activity__length
- updated_issues_count_activity__length
- updated_issues_count_community__length
- is_maintained_codequality__length
- active_C1_pr_comments_contributor_activity__length
- comment_frequency_activity__length
- active_C1_pr_create_contributor_activity__length
- code_quality_guarantee_codequality__length
- contributor_count_codequality__length
- commit_frequency_inside_codequality__length
- contributor_count_group_activity__length
- contributor_count_without_bot_group_activity__length
- contributor_count_bot_group_activity__length
- commit_frequency_codequality__length
- git_pr_linked_ratio_codequality__length
- commit_frequency_inside_without_bot_codequality__length
- commit_frequency_inside_bot_codequality__length
- commit_frequency_bot_codequality__length
- active_C1_pr_comments_contributor_codequality__length
- commit_frequency_bot_group_activity__length
- contributor_count_bot_activity__length
- pr_commit_count_codequality__length
- lines_added_frequency_codequality__length
- pr_open_time_avg_community__length
- commit_frequency_without_bot_group_activity__length
- contributor_org_count_group_activity__length
- issue_first_reponse_avg_community__length
- LOC_frequency_codequality__length
- active_C2_contributor_count_codequality__length
- commit_frequency_activity__length
- organizations_activity_group_activity__length
- active_C1_issue_comments_contributor_activity__length
- closed_prs_count_community__length
- pr_merged_count_codequality__length
- pr_commit_linked_count_codequality__length
- commit_frequency_org_percentage_group_activity__length
- community_support_score_community__minimum
- updated_since_activity__mean_abs_change
- activity_score_activity__sum_values
- closed_prs_count_community__minimum
- code_quality_guarantee_codequality__sum_values
- commit_frequency_org_percentage_group_activity__maximum
- activity_score_activity__minimum
- pr_merged_count_codequality__minimum
- commit_frequency_codequality__sum_values
- commit_frequency_activity__sum_values
- contributor_count_codequality__minimum
- commit_frequency_without_bot_codequality__sum_values
- commit_frequency_without_bot_activity__sum_values
- contributor_count_without_bot_codequality__minimum
- community_support_score_community__mean
- pr_commit_count_codequality__sum_values
- active_C2_contributor_count_codequality__sum_values
- active_C2_contributor_count_activity__sum_values
- closed_prs_count_community__sum_values
- pr_count_codequality__minimum
- commit_frequency_org_percentage_group_activity__mean
- commit_frequency_codequality__mean
- commit_frequency_activity__mean
- commit_frequency_without_bot_codequality__mean
- commit_frequency_without_bot_activity__mean
- activity_score_activity__mean
- contributor_org_count_group_activity__sum_values
- updated_since_activity__sum_values
- pr_count_codequality__sum_values
- pr_commit_count_codequality__mean
- commit_frequency_org_group_activity__absolute_sum_of_changes
- commit_frequency_codequality__absolute_sum_of_changes
- commit_frequency_activity__absolute_sum_of_changes
- commit_frequency_without_bot_activity__absolute_sum_of_changes
- commit_frequency_without_bot_codequality__absolute_sum_of_changes
- commit_frequency_org_group_activity__sum_values
- closed_prs_count_community__absolute_sum_of_changes
- pr_count_codequality__absolute_sum_of_changes
- closed_prs_count_community__mean
- code_quality_guarantee_codequality__mean
- active_C2_contributor_count_codequality__mean
- active_C2_contributor_count_activity__mean
- pr_merged_count_codequality__sum_values
- pr_commit_count_codequality__absolute_sum_of_changes
附录 B 参与特征提取的指标
共有 4 个方面,72 个指标参与了特征的计算
B.1 活跃度相关指标
- contributor_count_activity,
- contributor_count_bot_activity,
- contributor_count_without_bot_activity,
- active_C2_contributor_count_activity,
- active_C1_pr_create_contributor_activity,
- active_C1_pr_comments_contributor_activity,
- active_C1_issue_create_contributor_activity,
- active_C1_issue_comments_contributor_activity,
- commit_frequency_activity,
- commit_frequency_bot_activity,
- commit_frequency_without_bot_activity,
- org_count_activity,
- comment_frequency_activity,
- code_review_count_activity,
- updated_since_activity,
- closed_issues_count_activity,
- updated_issues_count_activity,
- recent_releases_count_activity,
- activity_score_activity,
B.2 代码质量保障相关指标
- contributor_count_codequality,
- contributor_count_bot_codequality,
- contributor_count_without_bot_codequality,
- active_C2_contributor_count_codequality,
- active_C1_pr_create_contributor_codequality,
- active_C1_pr_comments_contributor_codequality,
- commit_frequency_codequality,
- commit_frequency_bot_codequality,
- commit_frequency_without_bot_codequality,
- commit_frequency_inside_codequality,
- commit_frequency_inside_bot_codequality,
- commit_frequency_inside_without_bot_codequality,
- is_maintained_codequality,
- LOC_frequency_codequality,
- lines_added_frequency_codequality,
- lines_removed_frequency_codequality,
- pr_issue_linked_ratio_codequality,
- code_review_ratio_codequality,
- code_merge_ratio_codequality,
- pr_count_codequality,
- pr_merged_count_codequality,
- pr_commit_count_codequality,
- pr_commit_linked_count_codequality,
- git_pr_linked_ratio_codequality,
- code_quality_guarantee_codequality,
B.3 社区服务与支撑相关指标
- issue_first_reponse_avg_community,
- issue_first_reponse_mid_community,
- issue_open_time_avg_community,
- issue_open_time_mid_community,
- bug_issue_open_time_avg_community,
- bug_issue_open_time_mid_community,
- pr_open_time_avg_community,
- pr_open_time_mid_community,
- pr_first_response_time_avg_community,
- pr_first_response_time_mid_community,
- comment_frequency_community,
- code_review_count_community,
- updated_issues_count_community,
- closed_prs_count_community,
- community_support_score_community,
B.4 协作开发相关指数
- contributor_count_group_activity,
- contributor_count_bot_group_activity,
- contributor_count_without_bot_group_activity,
- contributor_org_count_group_activity,
- commit_frequency_group_activity,
- commit_frequency_bot_group_activity,
- commit_frequency_without_bot_group_activity,
- commit_frequency_org_group_activity,
- commit_frequency_org_percentage_group_activity,
- commit_frequency_percentage_group_activity,
- org_count_group_activity,
- contribution_last_group_activity,
- organizations_activity_group_activity
附录 C 16 个特征函数
- length (长度): 这个特征函数计算数据集的长度,也就是数据中包含多少个数据点或样本。
- large_standard_deviation (大标准差): 这个特征函数用于检测数据中大于给定标准差的值的比例。可以通过设置不同的阈值(r 值)来确定何为大标准差。
- mean (均值): 这个特征函数计算数据集中所有数据点的平均值。
- maximum (最大值): 计算数据集中的最大值。
- minimum (最小值): 计算数据集中的最小值。
- sum_values (值之和): 这个特征函数计算数据集中所有数据点的总和。
- variance (方差): 计算数据集的方差,它衡量了数据点与均值之间的离散程度。
- skewness (偏度): 偏度用于衡量数据分布的偏斜程度,即数据分布是否左偏(负偏度)或右偏(正偏度)。
- kurtosis (峰度): 峰度衡��量了数据分布的尖峰度或平扁度,是数据分布形状的一个指标。
- absolute_sum_of_changes (绝对值之和的变化): 这个特征函数计算相邻数据点之间的绝对值之和的变化情况。
- mean_abs_change (平均绝对变化): 计算数据集中相邻数据点之间的平均绝对变化。
- mean_change (平均变化): 计算数据集中相邻数据点之间的平均变化。
- first_location_of_maximum (最大值的首次位置): 找到数据集中第一次出现最大值的位置。
- first_location_of_minimum (最小值的首次位置): 找到数据集中第一次出现最小值的位置。
- last_location_of_maximum (最大值的最后位置): 找到数据集中最后一次出现最大值的位置。
- last_location_of_minimum (最小值的最后位置): 找到数据集中最后一次出现最小值的位置。